多线程·并发编程
进程与线程
现代的计算机系统提供了许多漂亮的抽象,如下图所示:
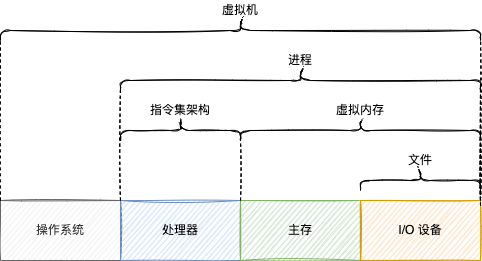
其中,进程是对处理器、主存和 I/O 设备的抽象,换言之,进程是操作系统对一个正在运行的程序的一种抽象。操作系统上可以“同时”运行多个进程,已经对一边听歌一边写代码和接收消息的流畅不足为奇,之所以用双引号,因为这可能是一种假象。
大多数计算机系统中,需要运行的进程数是多于可以运行它们的 CPU 个数的,那么所谓的”同时“运行,很有可能是模拟并发的假象;也就是说一个进程的指令和另一个进程的指令是被 CPU 交错执行的,而且 CPU 在进程间切换足够快,进程“暂停”和“恢复”的间隔也足够短,每个进程看上去像是连续运行。除非有多个 CPU 或多处理器的计算机系统,才能支持多进程并行,即处理器同时执行多个程序的指令。
一个进程用完了操作系统分配给它的时间片,操作系统决定把控制权转移给新的进程,就会进行上下文切换(context switch),即保存当前进程的状态,恢复目标进程的状态,交接控制权。这种状态被称为上下文(context),比如程序计数器和寄存器的当前值以及主存的内容。
一个进程可以存在多个控制流(control flow),它们被称为线程。如来自维基百科线程词条的插图所示:

因为只有单处理器,所以这个进程的两个线程轮番运行在进程的上下文中(模拟并发)。操作系统不仅调度进程,教科书常说,线程是操作系统调度的最小单位。大多数计算机系统中,需要运行的线程数大于可以运行它们的 CPU 核数,从单线程进程推广到多线程进程的线程,一个线程时间到了,上下文切换,它被“暂停”了,轮到了另一个线程运行,稍后轮到它时又“恢复”了。
多线程程序十分普遍。电脑和手机应用程序在用户界面渲染动画,同时在后台执行计算和网络请求。一个 Web 服务器一次处理数千个客户端的请求。多线程下载、多线程爬虫、多线程遍历文件树……多线程成为越来越重要的模型,因为多线程程序有不少优点。
多线程之间比多进程之间更容易共享数据和通信。同一个进程的多个线程共享进程的资源,比如进程的虚拟地址空间中的程序代码和程序处理的数据以及文件,对于同一进程的线程们来说,可执行代码只有一套,它们可以访问存储在堆 (Heap) 中的共享变量或全局变量,但是,栈(Stack)、包括程序计数器(Program Counter)在内的寄存器(Register)副本、线程本地存储(Thread Local Storage)都是线程私有的(如果有的话)。不仅如此,线程之间可以通过共享的代码、数据、文件进行通信,绝大部分情况下比进程间的通信更高效。
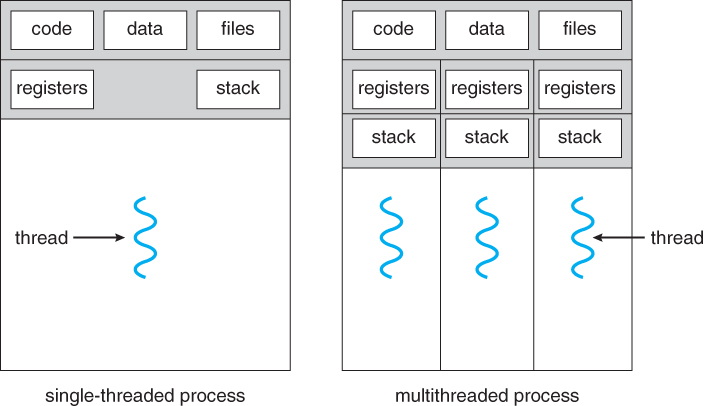
多线程执行任务更多或更快。如果主线程阻塞在耗时任务,整个程序可能会卡顿或长时间无响应,解决办法之一便是新建一个工作线程专门执行这个耗时任务,而主线程则继续执行其它任务。例如,前面提到的手机 APP(特别是 Android APP),UI 线程被阻塞后很有可能无法正常人机交互了,用户体验极差。更进一步,单进程的多线程之间的协作有可能提高 client-server 系统的性能,譬如异步调用缩短了请求响应时间(也许总延迟几乎没变)。最重要的是,虽然一个传统的 CPU 只能交错执行一个进程的多个线程,但随着多核处理器和超线程(hyperthreading)的普及,面对多任务或大任务的执行,多线程程序的性能上限具有更高的天花板,因为减少了执行多个任务需要模拟并发的开销,还因为处理器可以并行运行多个线程。
并发与并行
并发(Concurrency)和并行(Parallelism)这两个术语经常混淆,语义应当结合语境。
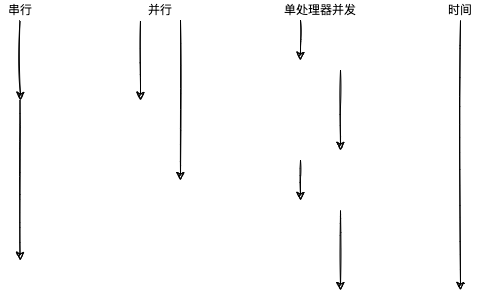
如上图所示,假设有两个任务和两个线程,每个任务只能由一线程执行且用时分别是 t1 和 t2(t1 < t2),且线程都是同时启动,那么各个方式总执行时间可能如下表所示:
| 方式 | 总执行时间 |
|---|---|
| 串行 | t1 + t2 |
| 并行 | t2 |
| 单处理器并发 | t1 + t2 + 上下文切换总时间 |
由此可见,如果上下文切换的耗时可以忽略不计,单处理器并发不仅执行总时间近似于串行执行总时间,还有一个优点是同时执行两个任务的假象。并行的方式非常快,但也取决于最耗时的任务。
在多处理器计算机系统中,多线程交错执行或并行执行都有可能出现,下文将”交错或并行“统称为”并发“。
Java 多线程
Java 进程
任何 Java 应用程序都跑在操作系统之上,操作系统作为硬件和应用程序的中间层,隐藏了下层具体实现的复杂性,并给上层提供了简单或统一的接口。

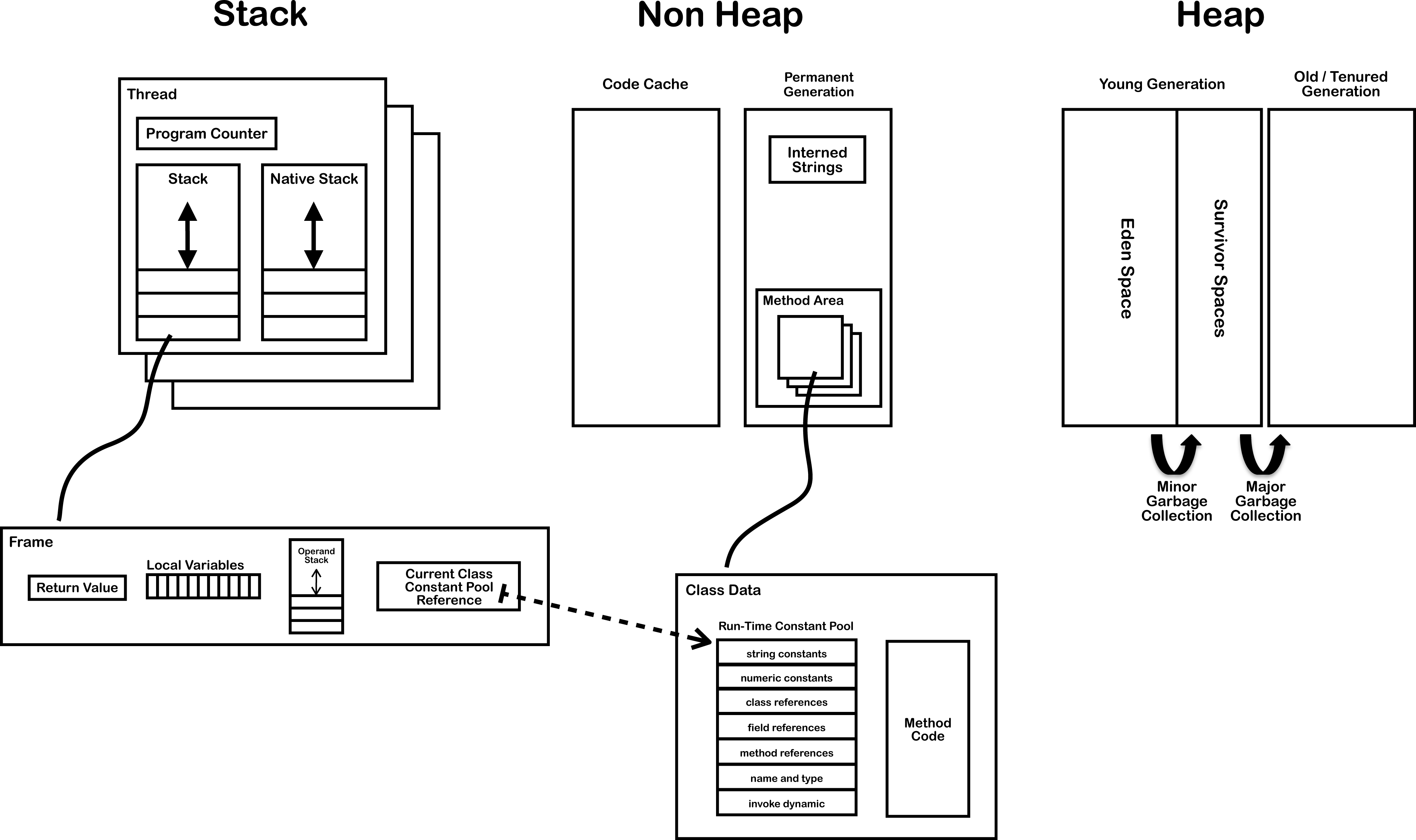
正在运行的 Java 程序就是 Java 虚拟机(JVM),而虚拟机是对整个操作系统的抽象,但对操作系统来说 JVM 仍然是进程。下面这张来自 JVM Internals 的图展示了 Java SE 7 虚拟机运行时的数据区域(Run-Time Data Areas)。图中的堆和栈类似于 Linux/Unix 操作系统进程的虚拟地址空间中的堆和栈,值得注意的是 Java 8 用元空间(Metaspace)代替了永久代(PermGen)。JVM 运行时的数据区域可分成两大类,一是 Java 线程共享区域,包括堆和方法区;二是 Java 线程私有区域,包括栈,详情请见 The Java Virtual Machine Specification, Java SE 8 Edition # 2.5. Run-Time Data Areas。
Java SE 最常用的虚拟机是 Oracle/Sun 研发的 Java HotSpot VM。HotSpot 基本的线程模型是 Java 线程与原生线程(native thread)之间 1:1 的映射。线程通常在操作系统层实现或在应用程序层实现,前者的线程称为内核线程,后者的线程可能称为用户线程。内核(kernel)是操作系统代码常驻主存的部分,而所谓用户,就是应用程序和应用程序开发者。
前文提到,充分利用多处理器能使多线程程序运行得更快。在操作系统层,消费多处理器的是内核线程,操作系统负责调度所有内核线程(原生线程)并派遣到任何可用的 CPU,因为 Java 线程与内核线程(原生线程)是一对一映射,所以充分利用多处理器能增强 Java 程序的性能。
启动线程
对于 HotSpot VM 来说,Java 线程是 java.lang.Thread 的实例。Java 用户可以使用类继承 java.lang.Thread 来新建和启动 Java 线程:
public class HelloThread extends Thread {
@Override
public void run() {
System.out.println("Hello from a thread");
}
public static void main(String[] args) {
new HelloThread().start();
}
}
或者使用类实现 java.lang.Runnable 来新建和启动线程。
public class HelloRunnable implements Runnable {
@Override
public void run() {
System.out.println("Hello from a thread");
}
public static void main(String[] args) {
new Thread(new HelloRunnable()).start();
}
}
Java 8 以上的用户也许更倾向于使用匿名内部类实现 java.lang.Runnable 或 Lambda 表达式简化以上代码,但都是通过调用 java.lang.Thread#start 方法来启动新线程,对应的原生线程(内核线程)在启动 Java 线程时创建,并在终止时回收。其中,run 方法是 Java 线程启动后执行的语句组,即人类要求它执行的任务,而 main 方法的语句是 Java 用户直接或间接通过命令行启动 JVM 后执行。
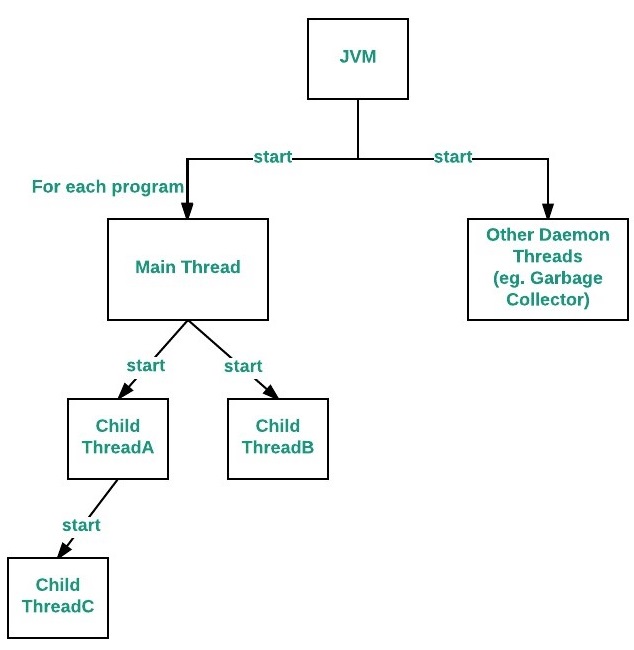
如上图所示,即使运行一个简单的 “Hello World” 程序,也可能在 JVM 或操作系统创建十几个或更多线程。例如执行 main 方法的语句需要的主线程,主线程能启动子线程并执行后续语句,子线程也能启动其子线程并执行后续语句,而且还有其它由 HotSpot 为了内部目的而创建的线程,如 VM thread、Periodic task thread、GC threads、Compiler threads、Signal dispatcher thread。
ThreadLocal
前面提到了线程有若干的私有区域,其中之一能在 java.lang.Thread 中找到数据结构。Thread 维护了一个类型为 java.lang.ThreadLocal.ThreadLocalMap 的字段,ThreadLocalMap 是一个定制化的 HashMap,key 的类型是 ThreadLocal,value 指代线程本地变量的值。
public class TransactionId {
private static final ThreadLocal<Long> tid = ThreadLocal.withInitial(() -> 0L);
public static Long get() {
return tid.get();
}
public static void set(Long value) {
tid.set(value);
}
}
如上所示,类型为 ThreadLocal 的字段初始化后,每个访问该字段(通过 get 或 set 方法)的线程访问的是各自 ThreadLocalMap 实例存储的 key/value,其中类型是 ThreadLocal 的 key 相等,但 value 不一定相等。
线程状态
下面这个来自 Java 6 Thread States and Life Cycle 的状态机,很好地描述了 Java 线程状态和生命周期。
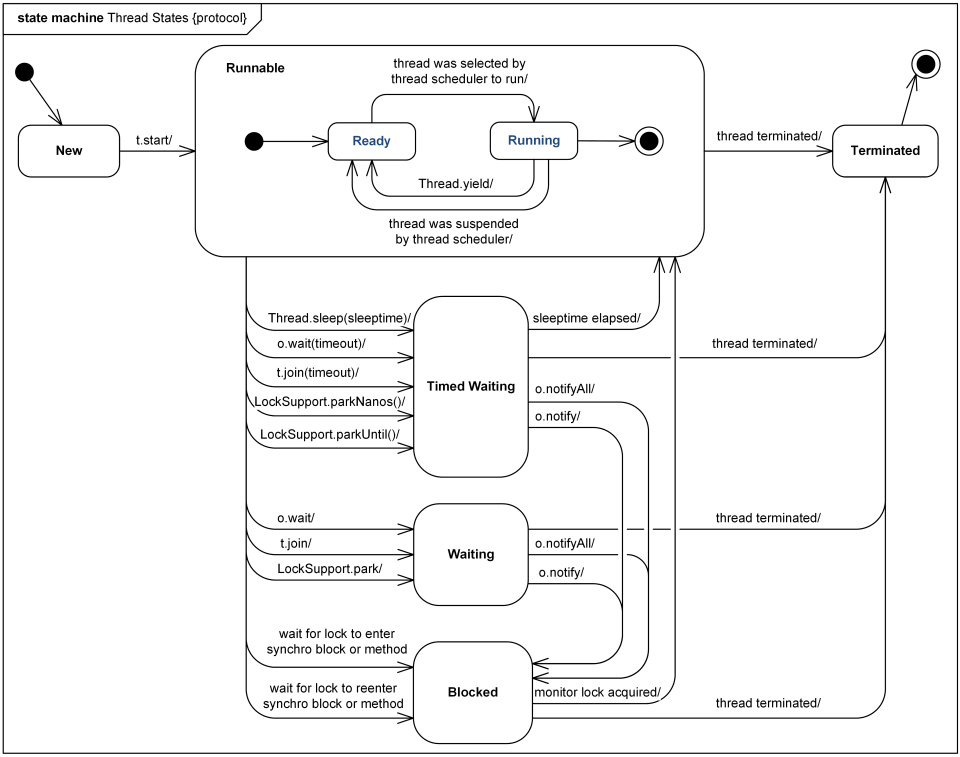
翻阅 JDK 8 的 java.lang.Thread.State 可以确定,在给定的时间点,一个 Java 线程只能处于以下状态之一:
- New。尚未启动的线程处于此状态。
- Runnable。Java 虚拟机中正在执行的线程处于此状态。
- Blocked。等待获得监视器锁(monitor lock)而被阻塞的线程处于此状态。
- Waitting。无限期地等待另一个线程执行特定操作的线程处于此状态。
- Timed Waiting。有限期地等待另一个线程执行特定操作的线程处于此状态。
- Terminated。终止的线程处于此状态。
如状态机所示,当线程执行不同操作时,线程状态发生转换,这些操作对应于 JDK 已提供的方法。注意上图的 o 表示 Object,t 表示 Thread。
通知
wait/notify
一个线程处于等待状态时,可以被另外一个线程通知,转为可运行状态。比如,一个线程用一个对象(的引用)调用 Object#wait(),另一个线程用同一个对象(的引用)调用 Object#notify() 或 Object#notifyAll(),前提是它们必须拥有该对象的内置锁;第一个线程调用 Object#wait() 时,它会释放该对象的内置锁并“暂停”,第二个线程获得该对象的内置锁成功之后,调用 Object#notifyAll() 通知所有曾经用同一个对象(的引用)调用了 Object#wait() 的线程有重要事情发生;在第二个线程释放了该对象的内置锁后的某个时刻,第一个线程重新获得了该对象的内置锁,并从 Object#wait() 返回而“恢复”。阻塞状态与内置锁或监视器锁息息相关,将在下文的"锁和同步"讨论。
详情请见 Object。
interrupt
另外,线程有一个中断状态(interrupt status)。所谓中断,即停止正在执行的操作,并执行其它操作。例如,主线程可使用子线程对象(的引用)调用 java.lang.Thread#interrupt() 中断子线程,子线程能够捕获 java.lang.InterruptedException 或调用 java.lang.Thread#interrupted() 接收到中断。
详情请见 Thread。
park/unpark
类比申请许可和提供许可。相比于 wait/notify,park/unpark 对调用顺序没有要求。线程调用 LockSupport#park() 时“暂停”,线程调用 LockSupport#unpark(Thread) 时取消给定线程的“暂停”,如果给定线程已“暂停”,则给定线程从 LockSupport#park() 返回而“恢复”,如果给定线程没有“暂停”,那么将来给定线程第一次调用 LockSupport#park() 时立即返回。
详情请见 LockSupport。
spurious wakeup
中断和虚假唤醒可能发生,官方建议在循环体内使用 wait 和 park,如下所示:
synchronized (obj) {
while (<condition does not hold>) {
obj.wait();
}
... // Perform action appropriate to condition
}
或者:
while (waiters.peek() != current || !locked.compareAndSet(false, true)) {
LockSupport.park(this);
// ignore interrupts while waiting
if (Thread.interrupted()) {
wasInterrupted = true;
}
}
线程池
使用 Thread.start(...) 启动线程足以执行基本的任务,但是对于复杂任务,例如有返回值的任务和定时任务等,其 API 过于低级。大规模的应用程序中,将线程的创建和管理从应用程序其余部分分开是很有意义的,理由之一是分离关注点能够减弱复杂性。封装了线程的创建和管理的对象们称为 Executors。JDK 的 java.util.concurrent 包定义了三代 Executor 接口:
如果 r 是 Runnable 对象,而 e 是 Executor 对象,则可以使用
e.execute(r);
代替
new Thread(r).start();
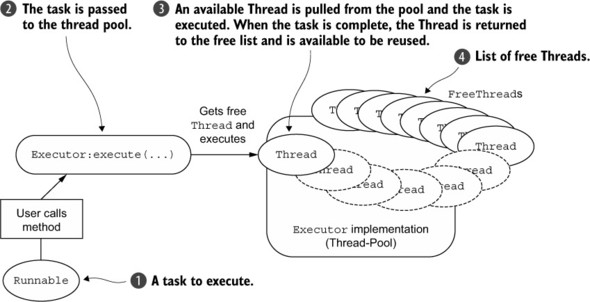
Executor 接口大部分实现都使用线程池(Thread Pool),这就是理由之二。例如,一个一般的服务器端程序服务着多个客户端,如果每个客户端的请求都通过新建一个线程来处理,即线程数随着请求数增加而增加,虽然新建线程比新建进程便宜,但是当活跃的线程数太多时,不仅占用大量的内存,容易导致内存溢出,而且操作系统内核需要花费大量的时间在线程调度上(上下文切换),大量的线程“暂停”较长时间,还因频繁新建和终结执行短时任务的线程而引起的延迟,大量客户端长时间得不到响应。
对于 Java Hotspot VM 来说,大量线程的另一个问题是巨大的根集合(root set),因此 GC 停顿阶段(stop-the-world pause)更长。
线程池由数量可控的工作线程(worker thread) 组成,每个工作线程的生命都被延长,以便用于执行多个任务,既减少了上下文切换引起的延迟,也减少了频繁新建和终结执行短暂任务的线程而引起的延迟。线程池的新建通常是预处理,即服务器端程序提供服务之前已准备好线程池,避免了临时新建大量线程的开销。
线程池有一种类型是固定线程池(fixed thread pool),如果某个线程仍在使用中而被某种方式终止,那么就会有新的线程代替它。任务通过队列提交到池中,任务队列可以容纳超过线程池中线程数量的的任务。这样设计的好处是优雅降级(degrade gracefully)和削峰。
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>());
}
上面是 Executors 的新建固定线程池的简单方法。注意当中的参数类型,LinkedBlockingQueue,它是 BlockingQueue 的基于链表的实现类,作为阻塞队列,它有一个特性,当队列为空时,线程从队列拉取元素会被阻塞或被迫等待。仔细翻阅源码,可以知道线程池的预先新建和工作线程的生命延长是通过阻塞工作线程或使之有限期等待来实现。除此之外,任务队列的的任务抽象为 Runable。
新建线程池返回一个 ExecutorService 实例,利用它来提交任务:
Future<?> future = executorService.submit(() -> {
// do something
});
submit 方法可传递 Runable 引用或 Callable 引用,两者的关系如下:
Runnable runnable = new FutureTask<>(callable);
Future 表示异步结果。主线程调用 Future#get 方法时被迫等待,直到子线程完成相应的任务后,主线程从 Future#get 方法返回得到结果并执行后续语句。
CompletableFuture 实现了 Future,并且支持设置回调方法。主线程无需等待工作线程完成相应的任务,当工作线程完成相应的任务后,回调方法会被调用。
CompletableFuture<Object> future = CompletableFuture.supplyAsync(() -> {
// do something
}, threadPoolExecutor);
future.thenCompose(obj -> CompletableFuture.supplyAsync(() -> {
// do other things
}), threadPoolExecutor);
future.whenComplete((obj, e) -> {
// callback
}, threadPoolExecutor);
设想一下多线程并发处理事件,要求主线程等待所有任务完成。
List<CompletableFuture<Event>> futures = new ArrayList<>(events.size());
for (Event event : events) {
CompletableFuture<Event> future = CompletableFuture.supplyAsync(() -> {
// handle event
return event;
}, threadPoolExecutor);
futures.add(future);
}
CompletableFuture<Void> allFuture = CompletableFuture.allOf(futures.toArray(new CompletableFuture[0]));
try {
allFuture.join();
} catch (Exception e) {
// ...
}
使用 Executors 新建线程池,需要注意的是,可能会因为任务队列堆积过多任务从而导致内存溢出,因为 LinkedBlockingQueue 可自动扩容,最大值为 Integer.MAX_VALUE。建议合理设置线程池的各个参数,例如使用构造器新建线程池:
new ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler);
提交任务后,可能的情况如下所示:
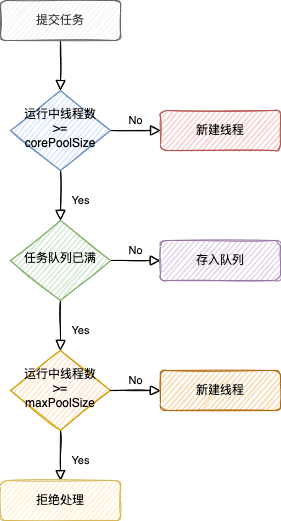
详情见 ThreadPoolExecutor 和 ScheduledThreadPoolExecutor。
Fork/Join
Fork/Join 框架是 ExecutorService 接口的实现,它是为了可以分而治之的任务或工作而设计的,目标是使用所有可用的处理器来提高应用程序的性能。Fork/Join 框架分配任务给线程池中的工作线程,但是与一般的线程池不一样,它使用工作窃取算法,空闲的工作线程可以窃取繁忙的工作线程的任务来执行,这个线程池称为 ForkJoinPool。
工作线程很有可能会被 BOSS 命令按以下套路工作:
if 我的工作量足够小
直接做工作
else
将我的工作分为两个片段
调用两个片段并等待结果
分而治之,通常把一个足够大的工作任务递归分解为两个或多个相同或相似的子任务。
public class BigTask extends RecursiveAction {
private long[] src;
private int start, len;
// ...
public BigTask(long[] src, int start, int len) {
this.src = src;
this.start = start;
this.len = len;
}
protected static int threshold = 1000;
@Override
protected void compute() {
if (len < threshold) {
// 直接操作 src
} else {
int split = len / 2;
invokeAll(new BigTask(src, start, split),
new BigTask(src, start + split, len - split));
// ...
}
}
}
假设这个大任务(BigTask)是对一个很长的数组(src)进行某些操作,例如排序、map、reduce、过滤、分组等。其中 BigTask 继承了 RecursiveAction,重写了 compute 方法。然后,新建一个线程池,命令工作线程执行大任务。
long[] src = ...;
BigTask task = new BigTask(src, 0, src.length);
ForkJoinPool pool = new ForkJoinPool();
pool.invoke(task);
一个工作线程调用了 compute 方法,先判断当前 src 的长度是否小于阈值(threshold),若是则认为这个任务足够小,单线程很快就能完成对 src 的操作,否者就认为这个任务足够大,需要分工,于是先把 src 分成两个片段,然后调用 invokeAll 方法,其它工作线程去执行这两个子任务,又调用了 compute 方法……在多处理器计算机系统中,因为支持多线程并行,所以这类程序通常运行得很快。
如果需要返回值,则可以使用 RecursiveTask。
public class FibonacciTask extends RecursiveTask<Integer> {
private int n;
public FibonacciTask(int n) {
this.n = n;
}
@Override
protected Integer compute() {
if (n <= 1) {
return n;
}
FibonacciTask f1 = new FibonacciTask(n - 1);
f1.fork();
FibonacciTask f2 = new FibonacciTask(n - 2);
return f2.compute() + f1.join();
}
public static void main(String[] args) throws ExecutionException, InterruptedException {
ForkJoinPool pool = new ForkJoinPool
(Runtime.getRuntime().availableProcessors(),
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
ForkJoinTask<Integer> task = pool.submit(new FibonacciTask(10));
Integer result = task.get();
}
}
先分解,后合并。
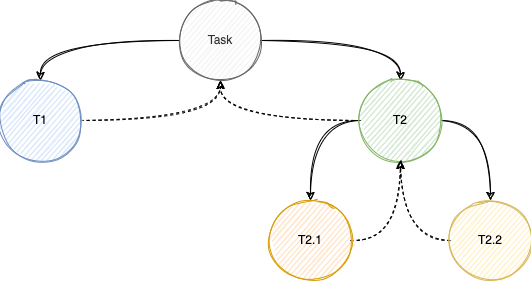
JDK 的 java.util.Arrays 和 java.util.streams 提供了许多操作聚合类型实例的并行化方法,这些方法通常基于 Fork/Join。
非线程安全
前面说到了多线程程序的优点,但它也有明显的缺点。因为多个线程并发执行,且多个线程共享同一份只读代码,当多个线程并发读写共享变量或全局变量时,可能出现线程干扰(thread interference)和内存一致性错误(memory consistency errors),从而无法保证程序功能正确,也称为线程不安全。
public class Counter {
private long count;
public void increment() {
count++;
}
public long value() {
return count;
}
}
上面是一个简单的计数器(Counter),其中有一个将计数器的值(count)增加 1 的方法(increment)。从人脑的角度,increment 方法可分解为三个步骤:
- 读取 count 的值。
- 计算 count + 1。
- 把计算结果写回 count。
从计算机处理器的角度:
- 从主存复制 count 的值和 1 的值到两个寄存器,以覆盖寄存器原来的值。
- 把两个寄存器的值复制到 ALU,ALU 对这两个值做算术运算。
- ALU 将运算结果存入一个寄存器,以覆盖该寄存器原来的值。
假设两个线程读取了 count 的值为 0,两个线程都在计算 0 + 1,一个线程比另一个线程更快把计算结果写回 count,此时 count 的值为 1,较慢的线程把 1 写回了 count,最终 count 的值是错误的 1,而不是正确的 2。在转账场景下,相互覆盖或丢失更改是一个非常严重的错误,例如两个人同时对一个银行账户进行取款或存款,如果银行软件系统开发者仍然有线程惯性,那么结果可能取多了金额或存少了金额。
| 线程 1 | 线程 2 | 整数值 | |
|---|---|---|---|
| 0 | |||
| 读取 | <- | 0 | |
| 读取 | <- | 0 | |
| 增加 | 0 | ||
| 增加 | 0 | ||
| 写回 | -> | 1 | |
| 写回 | -> | 1 |
下面通过 Junit 测试,来证实线程不安全的存在。
public class CounterTest {
private static final long wait = 3000;
private final long threads = 2;
private final long times = 1000000;
private final long excepted = threads * times;
@Test
public void testIncrement() throws InterruptedException {
Counter counter = new Counter();
startThreads(counter, () -> {
for (int j = 0; j < times; j++) {
counter.increment();
}
System.out.printf("threadName: %s, counterValue: %s\n", Thread.currentThread().getName(), counter.value());
});
Assert.assertNotEquals(excepted, counter.value());
}
private void startThreads(Counter counter, Runnable runnable) throws InterruptedException {
for (int i = 0; i < threads; i++) {
new Thread(runnable).start();
}
Thread.sleep(CounterTest.wait);
System.out.printf("threadName: %s, exceptedCounterValue: %s, actualCounterValue: %s\n", Thread.currentThread().getName(), excepted, counter.value());
}
}
一个临时测试线程调用了 testIncrement 方法,启动了 2 个子线程,为了避免其中一个线程已经停止了,而另外一线程启动中,模拟了一个耗时任务,两个线程都要重复调用 Counter 的 increment 方法 1000000 次。注意,临时测试线程跳出循环后,会睡眠 3000 毫秒,才继续往下执行,预期结果为 2000000(子线程数与递增次数的乘积)。此处省略本机信息,测试结果如下:

临时测试线程和两个子线程取得 count 的值都是错误的。根本原因是多线程并发访问共享变量或全局变量时,每个线程对该变量赋值前的值与它读取的值不一致,最终导致了程序错误。结合上面提到的 JVM 运行时的数据区域,可以推断出 Java 各种变量是否线程安全。
| 变量 | 区域 | 是否线程共享 | 是否线程安全 |
|---|---|---|---|
| 实例字段(instance field) | 堆 | 是 | 否 |
| 静态字段(static field) | 堆 | 是 | 否 |
| 本地变量(local variable) | 栈 | 否 | 是 |
Java 并发编程
锁
保证多线程并发访问共享资源的程序正确,有一个直观的解决方案——锁(Lock)。
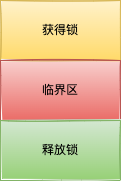
-
只有获得锁成功的线程才能进入临界区(critical section),访问共享资源。
-
访问共享资源完成后,即使过程发生异常,也一定要释放锁,退出临界区。
软件层的锁通常需要硬件层支持才能有效实现。这种支持通常采取一种或多种原子指令的形式,如 test-and-set、compare-and-swap、fetch-and-add。所谓原子指令,即处理器执行该指令不可分割且不可中断,换言之,原子操作要么完全发生,要么根本不发生。对于多处理器的计算机系统,为了保证原子性,甚至可能通过锁定总线,暂时禁止其它 CPU 与内存通信。
synchronized
以前文的计数器为例,新增一个用 synchronized 修饰的 incrementSyncMethod 方法到 Counter,
public class Counter {
private long count;
public void increment() {
count++;
}
public synchronized void incrementSyncMethod() {
count++;
}
public long value() {
return count;
}
}
使用与测试 increment 方法相同的测试数据,测试启动相同个数的子线程重复调用同一个 Counter 对象的 incrementSyncMethod 方法相同次数,测试代码如下:
@Test
public void testIncrementSyncMethod() throws InterruptedException {
Counter counter = new Counter();
startThreads(counter, () -> {
for (int j = 0; j < times; j++) {
counter.incrementSyncMethod();
}
System.out.printf("threadName: %s, counterValue: %s\n", Thread.currentThread().getName(), counter.value());
});
Assert.assertEquals(excepted, counter.value());
}
测试结果如下图所示:

测试通过,期望值(exceptedCounterValue)与实际值(exceptedCounterValue)相等,其中一个子线程(Thread-1)与临时测试线程(Time-limited test)读取的 count 值相等。
防止线程干扰和内存一致性错误的机制是同步(Synchronization)。关键字 synchronized,翻译为已同步。当只有一个线程调用一个同步方法,它会隐式获得该方法的对象的内置锁(intrinsic lock)或监视器锁(monitor lock),并在该方法返回时隐式释放该对象的内置锁(即使返回是由未捕获异常引起的)。如果是用 synchronized 修饰的静态方法,这个线程会获得该静态方法所属的类所关联的 Class 对象的内置锁,因此,通过不同于该类的任何实例的锁来控制对该类的静态字段的访问。
这足以解释上面的两个线程读写同一个变量重复百万次,最后结果仍然正确的原因。两个线程调用同一个同步方法,一个线程快于另一个线程获得了这个方法的对象的内置锁,较慢的线程则被迫等待或被阻塞,已拥有该对象的内置锁的线程执行该方法的语句,更改共享实例字段,该方法返回时隐式释放了该对象的内置锁,另一个线程有机会拥有该对象的内置锁……即使重复多次,一个时刻只能有一个线程正在访问共享实例字段,另一个线程被迫等待或被阻塞,也就是说这个两个线程对于共享实例字段的访问是互斥的,也就不会出现线程干扰和内存一致性错误。
| 线程 1 | 线程 2 | 整数值 | |
|---|---|---|---|
| 0 | |||
| 获得锁(成功) | 0 | ||
| 获得锁(失败) | 0 | ||
| 读取 | <- | 0 | |
| 增加 | 0 | ||
| 写回 | -> | 1 | |
| 释放锁 | 1 | ||
| 获得锁(成功) | 1 | ||
| 读取 | <- | 1 | |
| 增加 | 1 | ||
| 写回 | -> | 2 | |
| 释放锁 | 2 |
编写同步代码的另一个方式是使用同步语句(Synchronized Statements),比如,改写一下测试方法:
@Test
public void testIncrementSyncBlock() throws InterruptedException {
Counter counter = new Counter();
startThreads(counter, () -> {
for (int j = 0; j < times; j++) {
synchronized (counter) {
counter.increment();
}
}
System.out.printf("threadName: %s, counterValue: %s\n", Thread.currentThread().getName(), counter.value());
});
Assert.assertEquals(excepted, counter.value());
}
或者添加一个 incrementSyncStmt 方法到 Counter 类,以及新增对应的测试用例:
public class Counter {
private long count;
public void increment() {
count++;
}
public synchronized void incrementSyncMethod() {
count++;
}
public void incrementSyncStmt() {
synchronized (this) {
count++;
}
}
public long value() {
return count;
}
}
@Test
public void testIncrementSyncStmt() throws InterruptedException {
Counter counter = new Counter();
startThreads(counter, () -> {
for (int j = 0; j < times; j++) {
counter.incrementSyncStmt();
}
System.out.printf("threadName: %s, counterValue: %s\n", Thread.currentThread().getName(), counter.value());
});
Assert.assertEquals(excepted, counter.value());
}
采用同步语句需要显式指定一个提供内置锁的对象,同步语句建立临界区,多线程互斥访问该对象的状态(实例字段或静态字段)。
膨胀
每一个 Java 对象都有一个与之关联的内置锁或监视器锁,其内部实体简称为监视器(monitor),又称为管程。因为有关键字 synchronized,所以每个 Java 对象都是一个潜在的监视器。一个线程可以锁定或解锁监视器,并且在任何时候只能有一个线程拥有该监视器。只有获得了监视器的所有权后,线程才可以进入受监视器保护的临界区。这与上文对内置锁的讨论一致,获得锁和释放锁可对应于 JVM 指令集的 monitorenter 和 monitorexit,即线程进入监视器和退出监视器。
如果对 Counter.class 进行反汇编:
javap -v target/classes/io/h2cone/concurrent/Counter.class
那么可以看到同步方法和同步语句的可视化字节码。
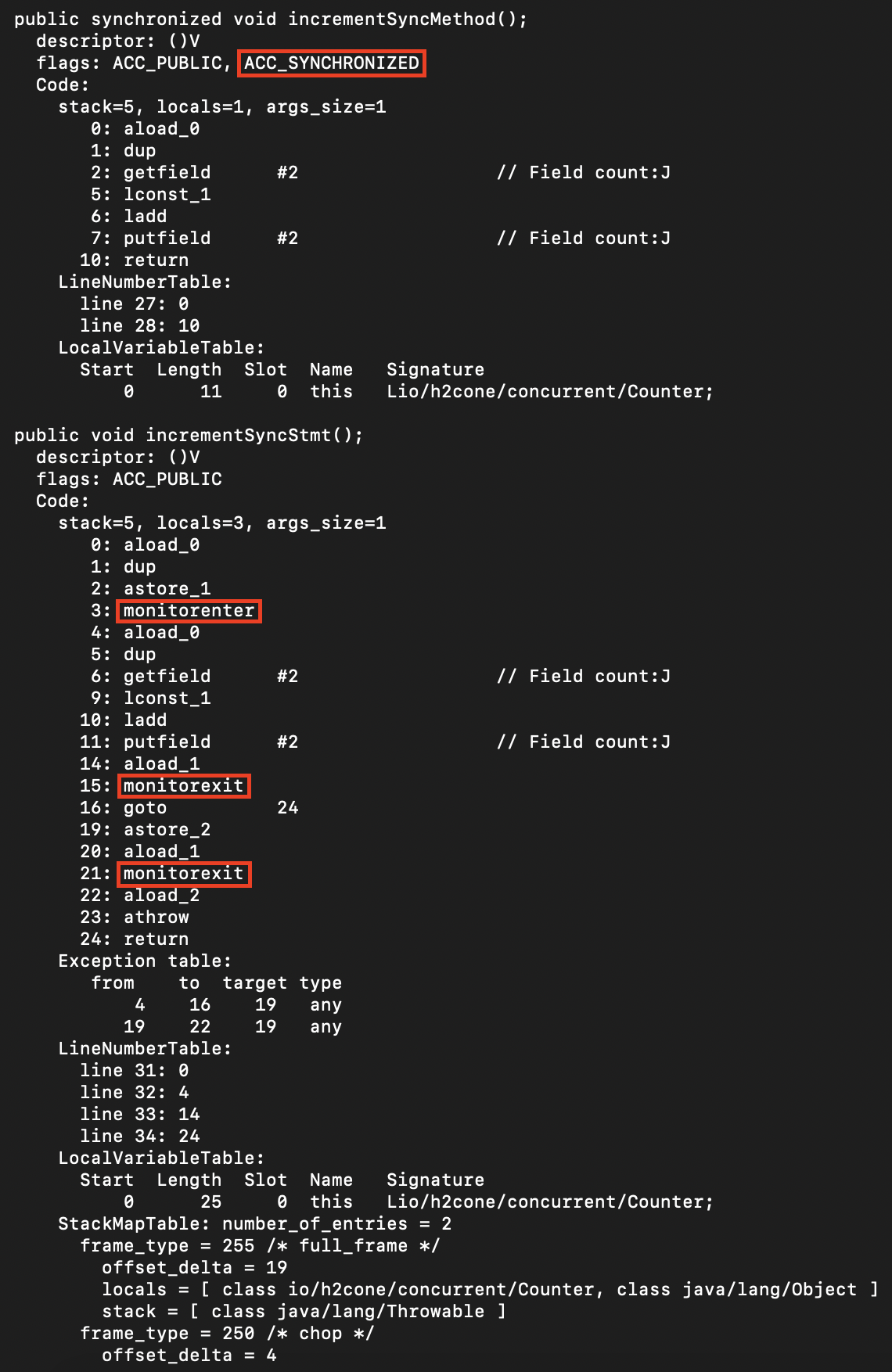
同步方法虽然使用一个名为 ACC_SYNCHRONIZED 的 flag,但从 Java 虚拟机规范可以知道,底层行为也应该是进入监视器和退出监视器。
在 Java Hostspot VM 中,每一个 Java 对象的内存布局都有一个通用的**对象头(object header)~**结构。对象头的第一个字是 mark word,第二字是 klass pointer。

-
mark word。通常存储同步状态(synchronization state)和对象的 hash code。在 GC 期间,可能包含 GC 状态。
-
klass pointer。指向另一个对象(元对象),该对象描述了原始对象的布局和行为。
-
普通对象头一般有 2 个字(word),数组对象头一般有 3 个字(word)。
锁的信息被编码在在对象头的 mark word,Mark word 最低两位的值(Tag)包含了对象的同步状态:
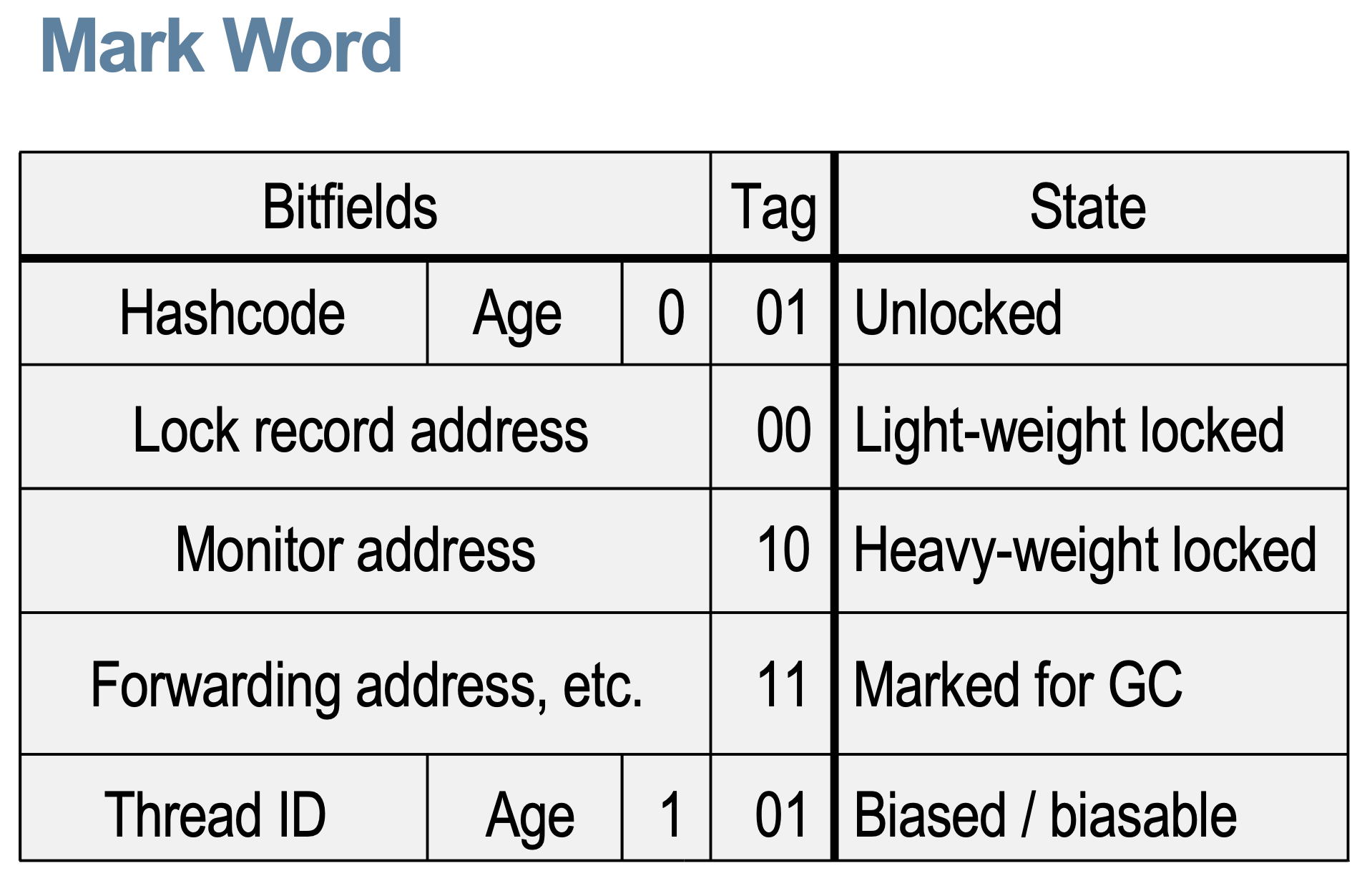
- 未锁定/已解锁(Unlocked)。没有线程拥有该对象的锁。
- 轻量级已锁定(Light-weight locked)。某个线程拥有该对象的轻量级锁。
- 重量级已锁定(Heavy-weight locked)。某个线程拥有该对象的重量级锁。
- 有偏向/可偏向(Biased / Biasable)。该对象已偏向或可偏向于某线程。
下图描述了对象同步状态的转换,也是锁状态的转换。
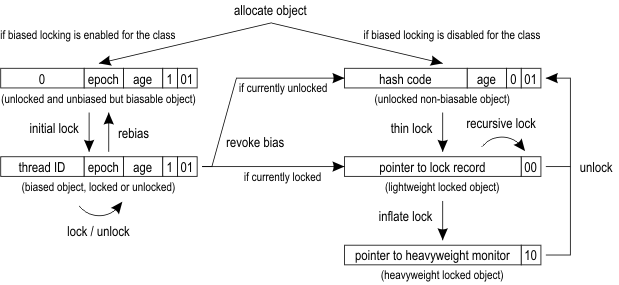
如果一个类的“可偏向”被禁用,该类的实例或对象的同步状态始于未锁定,即右手边。
- 当一个线程调用该对象的同步方法或执行了指定该对象的同步语句,Mark word 副本和指向对象的指针存储在该线程当前栈帧(frame)内的锁记录(lock record)中。
- JVM 尝试通过 compare-and-swap(CAS)在该对象的 mark word 中安装一个指向锁记录的指针(pointer to lock record)。
- 如果 CAS 操作成功,则该线程拥有了该对象的锁。该对象的 mark word 最后两位的值是 00。该锁称为轻量级锁。
- 如果是递归或嵌套调用作用于该对象的同步代码,锁记录初始化为 0,而不是该对象的 mark word。
- 如果 CAS 操作失败,则说明该对象已被其它线程锁定成功。JVM 首先检测该对象的 mark word 是否指向当前线程的栈。
- 如果 CAS 操作成功,则该线程拥有了该对象的锁。该对象的 mark word 最后两位的值是 00。该锁称为轻量级锁。
- 当多个线程并发锁定同一个对象,且竞争足够激烈时,轻量级锁升为重量级锁。重量级锁就是监视器,监视器管理等待的线程。等待获得监视器的线程状态就是“线程状态”所说的阻塞。
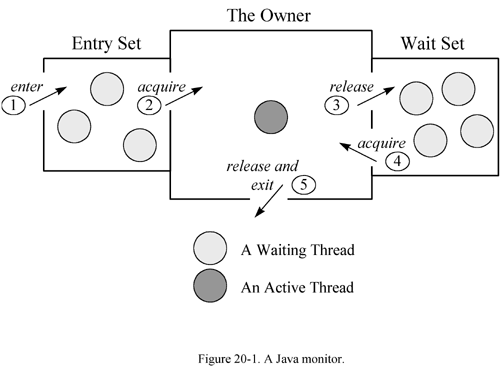
- JVM 使用的监视器类型可能如上图所示,该监视器由三个房间组成。中间只有一个线程,即监视器所有者。在左侧,一个小房间包含了入口集(entry set)。在右侧,另一个小房间包含了等待集合(wait set)。那么如果此 Java 监视器未过时,被阻塞的线程更可能处于入口集,因为等待集中的线程状态是“线程状态”所说的等待。
- 轻量级锁比重量级锁便宜很多,因为避免了操作系统互斥锁/条件变量(mutex / condition variables)与每个对象的联动。
- 如果有多个线程并发锁定共享对象,获得轻量级锁失败的线程通常不会被阻塞或被迫等待,而是自旋若干次,尝试获得锁。HotSpot VM 使用高级自适应自旋技术(advanced adaptive spinning techniques)来提高程序吞吐量,即使是锁定共享对象竞争激烈的程序。
如果一个类的“可偏向”已启用,该类的实例或对象的同步状态始于未锁定,且无偏向,即左手边。
- 据说,获得轻量锁的 CAS 在多处理器计算机系统上可能引起较大延迟,也许大多数对象在其生命周期中最多只能被一个线程锁定。早在 Java 6,此问题试图通过偏向锁优化。
- 该对象被第一个线程锁定时,只执行一次 CAS 操作,以将该线程 ID 记录到该对象的 mark word 中。于是该对象偏向于该线程。将来该线程对该对象的锁定和解锁无需任何原子操作或 mark word 的更新,甚至该线程栈中的锁记录也不会初始化。
- 当一个线程锁定已偏向于另一个线程的对象,该对象的偏向会被撤销(此操作必须暂停所有线程)。一般由偏向锁转为轻量级锁。
- 偏向锁的设计对一个线程重新获得锁更便宜和另一个线程获得锁更昂贵做了权衡:
- 如果某个类的实例在过去频繁发生便偏向撤销,则该类将禁用“可偏向”。这个机制叫做批量撤销(bulk revocation)。
- 如果一个类的实例被不同的线程锁定和解锁,且不是并发,则该类的实例被重置为已解锁且无偏向,但仍是可偏向的对象,因为该类的“可偏向”不会被禁用。这个机制叫做批量重置偏向(bulk rebiasing)。
- 当然可以从一开始就禁用偏向锁,启动 HotSpot VM 时指定关闭
UseBiasedLocking:
-XX:-UseBiasedLocking
对于一些程序,偏向锁弊大于利,例如 Cassandra 就禁用了它。
简而言之,从 Java 6 开始就对 synchronized 做了不少优化,随着多线程锁定共享对象的竞争强度增大,锁的状态一般由偏向锁升为轻量级锁,竞争足够激烈时,则升为重量级锁,这个过程称为膨胀(inflate)。
消除
在某些情况下,JVM 可以应用其它优化。例如,StringBuffer,它有很多同步方法。
{
StringBuffer sb = new StringBuffer();
sb.append("foo");
sb.append(v);
sb.append("bar");
return sb.toString();
}
如上所示,语句在某方法体内,因为 sb 是本地变量,所以调用 append 方法可以省略锁,这叫做锁消除(lock elision)。
粗化
{
sb.append("foo");
sb.append(v);
sb.append("bar");
}
再如上所示,如果 sb 是全局变量,且第一次 append 方法调用时已被某线程锁定成功,该线程可以避免 3 次锁定/解锁操作,而只需 1 次,这叫做锁粗化(lock coarsening)。
死锁
死锁描述了线程等待获得自己或对方已拥有的锁的僵持状态。
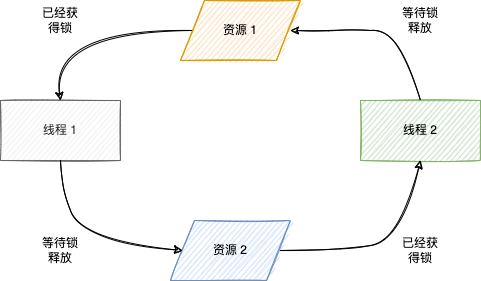
防止死锁的有效方案如下:
- 设置线程尝试获得锁的超时时间。
- 每个线程尝试获得多个资源的锁的顺序必须一致。
比如上图,线程 1 和线程 2 都需要获得资源 1 和资源 2 的锁,只要每个线程尝试获得资源的锁的顺序是 (1,2),也就不会是僵局。
惯用锁
除了 synchronized,JDK 提供的 java.util.concurrent 包,富有参差多态的锁。
ReentrantLock
ReentrantLock,可译为重入锁。重入(reentrant)是指一个线程可以再次拥有它已拥有且未释放的锁。通过上文“偏向锁和轻量级锁以及重量级锁”,可以知道内置锁是可重入锁。
public class Foobar {
public synchronized void doSomething() {
System.out.println("do something");
doOtherThings();
}
public synchronized void doOtherThings() {
System.out.println("do other things");
}
}
如上代码所示,当一个线程用 Foobar 对象调用 doSomething 方法,成功获得该对象的内置锁后,继续调用 doOther 方法时,假设内置锁不是重入锁,那么因为 doSomething 方法还未返回,所以该对象的内置锁还未自动释放,那么该线程将被迫无限期等待。
或者断言该线程调用以下方法不会引起 java.lang.StackOverflowError 异常:
public class Foobar {
public synchronized void doSomething() {
doSomething();
}
}
事实证明,以上断言都是错的。ReentrantLock 的一般用法如下:
final Lock lock = new ReentrantLock();
lock.lock();
try {
// critical section
} finally {
lock.unlock();
}
相比于 synchronized,Lock 要求显式锁定(lock)和解锁(unlock),因此要特别注意即使发生异常也要释放锁。如果不希望线程获得锁失败后等待机会而是继续前行或者需要返回结果,可以使用以下的方法:
- boolean tryLock();
- boolean tryLock(long time, TimeUnit unit) throws InterruptedException;
一个典型的用法可能是这样的:
if (lock.tryLock()) {
try {
// manipulate protected state
} finally {
lock.unlock();
}
} else {
// perform alternative actions
}
ReadWriteLock
ReadWriteLock,“读读共享,读写(写读)互斥,写写互斥”。
final ReadWriteLock readWriteLock = new ReentrantReadWriteLock();
Lock readLock = readWriteLock.readLock();
Lock writeLock = readWriteLock.writeLock();
readLock 和 writeLock 类似于共享锁和排他锁。
Semaphore
Semaphore,翻译为信号量,也可实现锁。
final Semaphore semaphore = new Semaphore(3);
semaphore.acquire();
semaphore.release();
如上所示,在同一时刻,最多只能有 3 个线程获得锁成功。
分类目录
下面这张图来自美团技术团队,描述了 Java 主流锁的分类目录:
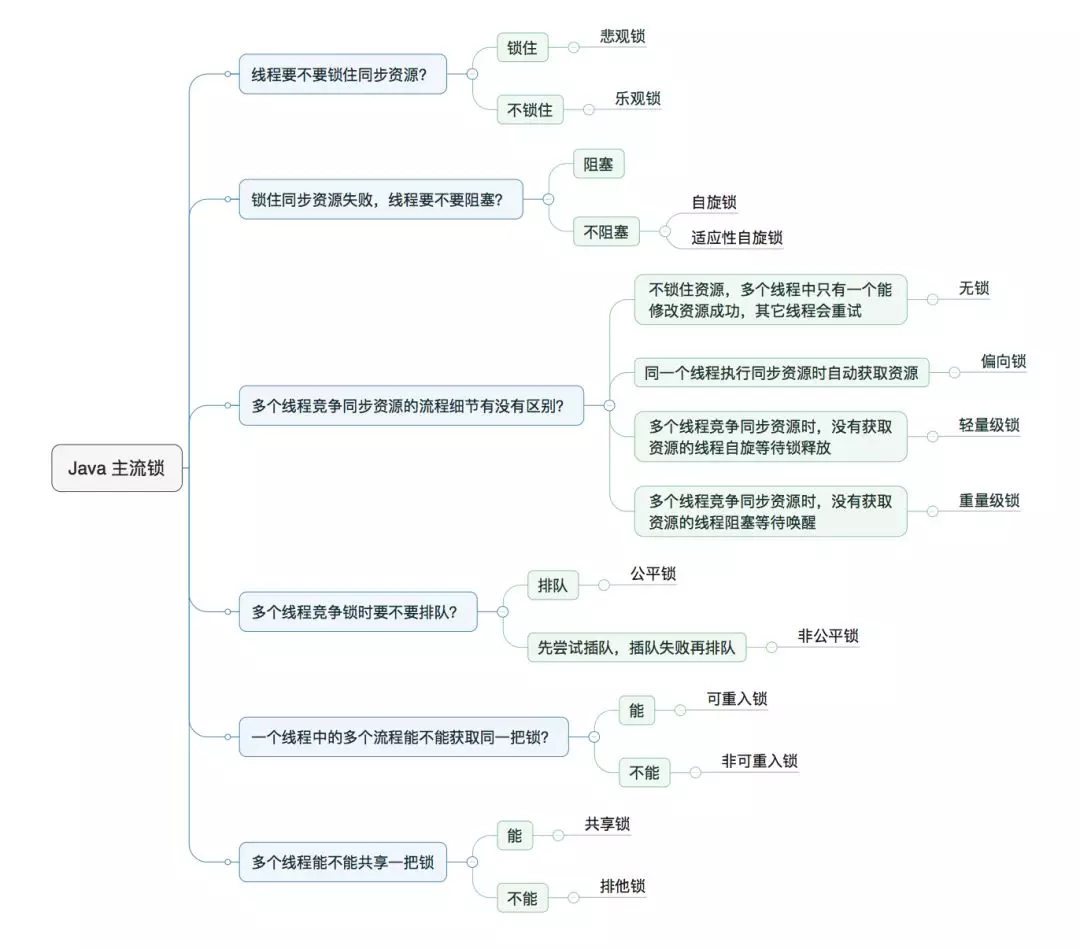
多线程竞争锁时,抢不到锁的线程,可能被迫等待(等待通知),或被阻塞(等待获得锁),抑或自旋。
协调
CountDownLatch
CountDownLatch,一个安全的且只能递减的计数器,支持一个线程等待多个线程完成任务后恢复执行。
final CountDownLatch latch = new CountDownLatch(2);
下降:
latch.countDown();
等待:
latch.await(3000, TimeUnit.MILLISECONDS);
如上所示,主线程调用 await 方法被迫等待,除非设置了超时时间,否则直到最后一个子线程完成任务后调用 countDown 方法把 latch 的次数减少为 0 时,才能继续前行。
CyclicBarrier
CyclicBarrier,调用 await 方法的线程被迫等待,直到给定数量的线程都到达“栅栏”,同时起跑。
final CyclicBarrier barrier = new CyclicBarrier(8);
等待:
barrier.await();
AQS
它们最亲近的父类是 AbstractQueuedSynchronizer。
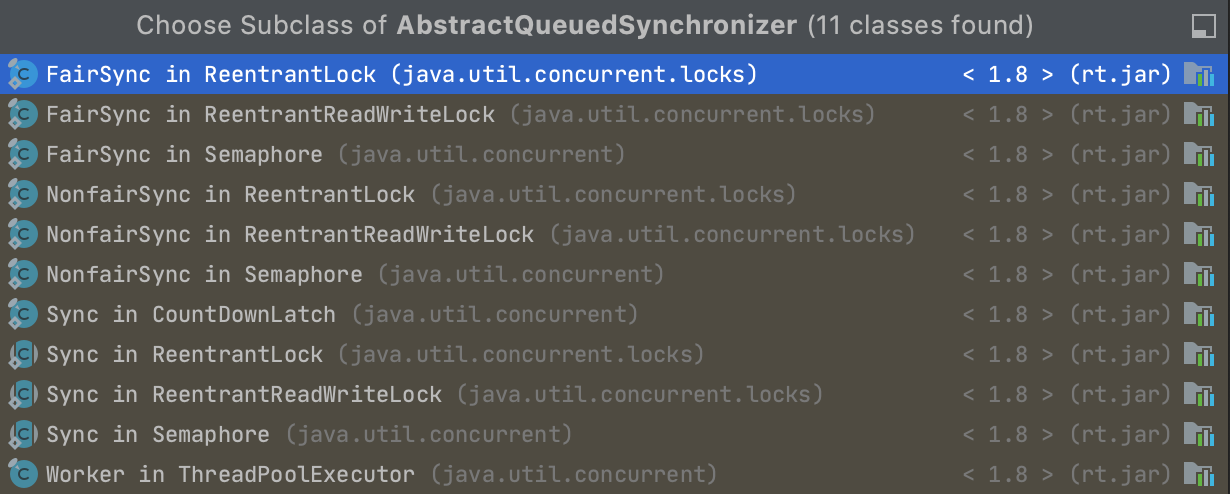
原子
保证多线程并发访问共享变量的程序正确,有另一个解决方案——原子操作。
原子访问
在 Java 中,对以下变量的读取或写入都属于原子访问(atomic access):
- 引用类型的变量和大部分原始类型的变量(除了
long和double的所有类型)。 - 声明为
volatile的所有变量(包括long和double变量)。
原子访问是指不可分且不可中断的操作,原子访问要么完全发生,要么根本不发生。虽然单一原子访问避免了线程干扰,但是不代表一组原子访问可以防止内存一致性错误。
使用 volatile 可降低内存一致性错误的风险,因为任何对 volatile 变量的写入都会与该变量的后续读取建立先发生在前的关系(happens-before relationship)。换言之,对 volatile 变量的更改始终对其它线程可见,即线程读取的 volatile 变量总是最新的。从 The Java Virtual Machine Specification, Java SE 8 Edition # 4.5. Fields 可以发现,ACC_VOLATILE 这个 flag 解释为 volatile 变量将永远不被 CPU 缓存。,只要 JVM 遵循了这个规范项,则线程只会从主存中读取而不是从其它高速缓存。volatile 另一个作用是避免指令重排导致线程对变量的更改不可见,因为现在的 HotSpot VM 默认开启了 JIT 编译器(Just-in-time compiler),在运行时 JIT 可能应用指令重排优化。
回想前文所讨论的“非线程安全”中的计数器(Counter),非同步的“当前值加一”分解出来的三个步骤是原子访问,但是试验证明,出现了相互覆盖或丢失更改。由上一段可知,即使使用 volatile 修饰 Counter 的 count 字段,非同步的“当前值加一”仍然会出现内存一致性错误。
到此为止,难道只能使用 synchronized 或 Java 锁防止线程干扰和内存一致性错误?然而并不是,还有一种 volatile 变量组合 CAS 循环的方案,其实前面”惯用锁“中所说的 ReentrantLock 的实现也使用了 CAS。
CAS
在“锁”中第一次提到了 compare-and-swap 这个指令,而在“偏向锁和轻量级锁以及重量级锁”中也提到了 CAS。CAS 的实现通常需要硬件层的支持,甚至可能在硬件层见到类似于软件层的锁概念。
现在用全新的 AtomicCounter 来代替那个混杂的 Counter。
public class AtomicCounter {
private AtomicLong count = new AtomicLong(0);
public void increment() {
long current, next;
while (true) {
current = count.get();
next = current + 1;
if (count.compareAndSet(current, next)) {
return;
}
}
}
public long value() {
return count.get();
}
}
- 使用
AtomicLong代替long,它维护了一个用volatile修饰的long字段。 - 使用核心是 CAS 的方法(CAS 循环)代替使用
synchronized的方法。
其中新的 increment 方法的循环体内的前两个步骤和在 “非线程安全” 所分解的前两个步骤是一致的,第三个步骤是关键:
count.compareAndSet(current, next)
当有多个线程并发调用 increment 方法,到了第三个步骤,某一个线程比较 count 绑定的字段与它前一次读取的 current 变量是否相等,如果相等,则把 count 绑定的字段的值设为 next 的值,increment 方法返回,如果不相等,则表明 count 绑定的字段已被其它线程更改,compareAndSet 方法返回 false,跳到第一步,继续尝试。竞争足够激烈时,相比于 synchronized,volatile 变量组合 CAS 循环是非阻塞方案。
compareAndSet 方法看似可分为两个步骤,实际上在底层,它是一个不可分且不可中断的原子指令,即从比较开始到赋值结束有且只有一个线程在执行此任务。该方法之所以可能返回 false,则是因为有可能一个线程赋值结束,与此同时,另一个线程开始比较。
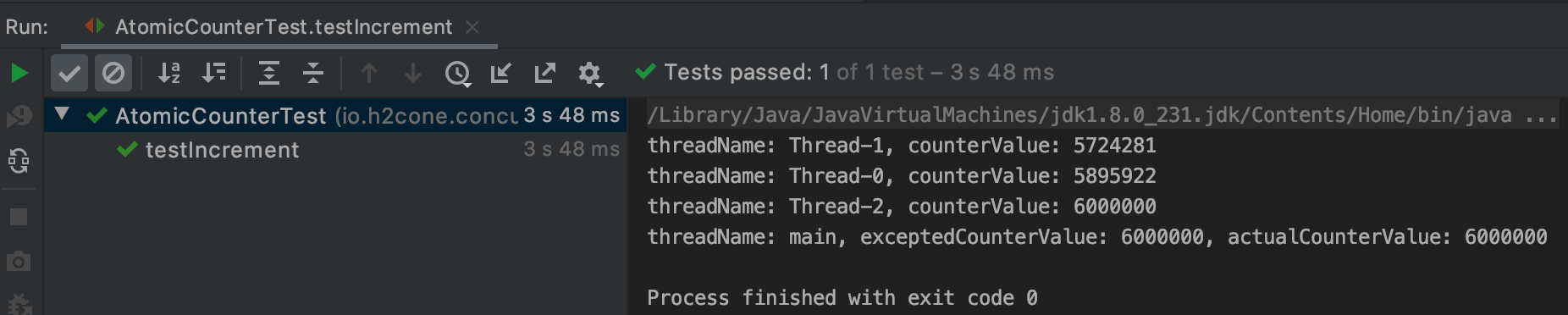
同样,也给 AtomicCounter 写测试类,这一次线程加一,次数加一百万。
public class AtomicCounterTest {
private static final long wait = 3000;
private final long threads = 3;
private final long times = 2000000;
private final long excepted = threads * times;
@Test
public void testIncrement() throws InterruptedException {
AtomicCounter counter = new AtomicCounter();
startThreads(counter, () -> {
for (int j = 0; j < times; j++) {
counter.increment();
}
System.out.printf("threadName: %s, counterValue: %s\n", Thread.currentThread().getName(), counter.value());
});
Assert.assertEquals(excepted, counter.value());
}
private void startThreads(AtomicCounter counter, Runnable runnable) throws InterruptedException {
for (int i = 0; i < threads; i++) {
new Thread(runnable).start();
}
Thread.sleep(AtomicCounterTest.wait);
System.out.printf("threadName: %s, exceptedCounterValue: %s, actualCounterValue: %s\n", Thread.currentThread().getName(), excepted, counter.value());
}
}
结果果然正确:
事实上,JDK 已经提供了许多操作原子类型实例的原子方法,上文最新版的“当前值加一”方法过于啰嗦,实际开发中请直接使用原子类的 incrementAndGet 方法。翻阅源码可以知道,原子类的 compareAndSet 方法使用了 sun.misc.Unsafe 的 compareAndSwap 方法:
public final native boolean compareAndSwapObject(Object var1, long var2, Object var4, Object var5);
public final native boolean compareAndSwapInt(Object var1, long var2, int var4, int var5);
public final native boolean compareAndSwapLong(Object var1, long var2, long var4, long var6);
注意其中的 native,也就是说,下层的 compareAndSwap 函数由 C/C++ 实现,而 Java 程序可通过 JNI 调用这个函数。
虽然 JDK 没有包含 sun.misc.Unsafe 的源文件,但是通过对 Unsafe.class反编译,可以确定 incrementAndGet 方法同样使用了 CAS 函数,并且也使用 CAS 循环。
public final long incrementAndGet() {
return unsafe.getAndAddLong(this, valueOffset, 1L) + 1L;
}
查看具体实现:
public final long getAndAddLong(Object var1, long var2, long var4) {
long var6;
do {
var6 = this.getLongVolatile(var1, var2);
} while(!this.compareAndSwapLong(var1, var2, var6, var6 + var4));
return var6;
}
注意,上文讨论的计数器在高并发场景中不一定是最优的方案,请看 LongAdder 和 LongAccumulator。
原子类
这个 java.util.concurrent.atomic 包定义了支持对单个变量进行原子操作的类。
值得注意的是,AtomicReference* 用于防止多线程并发操作引用类型实例出现线程干扰和内存一致性错误。
public class LinkedList<Item> {
private Node<Item> first;
static class Node<Item> {
Item item;
Node<Item> next;
}
public void push(Item item) {
Node<Item> oldFirst = first;
first = new Node<>();
first.item = item;
first.next = oldFirst;
}
}
如上所示,一个简略的链表(LinkedList),维护了一个首结点(first),push 方法用于在链表表头插入结点,当多线程并发调用同一个 LinkedList 实例的 push 方法时,它们存储了各自的老首结点(Node oldFirst = first;),它们新建了各自的新首结点(new Node<>();),然后把 first 指向各自的结点(first = new Node<>();),因为 first 是它们的共享变量,所以可能已经出现相互覆盖或丢失更改,更不用说后面了。
public class LinkedList<Item> {
private Node<Item> first;
static class Node<Item> {
Item item;
Node<Item> next;
}
public void push(Item item) {
Node<Item> oldFirst = first;
Node<Item> newFirst = new Node<>();
newFirst.item = item;
newFirst.next = oldFirst;
first = newFirst;
}
}
再如上所示,为了使问题清晰,只在 push 方法最后一步才设置 first。同样也因为 first 是它们的共享变量,所以它们都执行完最后一步后,可能出现一个或多个线程的新首结点游离于链表之外,因此,改用 CAS 方法:
public class AtomicLinkedList<Item> {
private AtomicReference<Node<Item>> first = new AtomicReference<>();
static class Node<Item> {
Item item;
Node<Item> next;
}
public void push(Item item) {
Node<Item> newFirst = new Node<>();
newFirst.item = item;
Node<Item> oldFirst;
while (true) {
oldFirst = first.get();
newFirst.next = oldFirst;
if (first.compareAndSet(oldFirst, newFirst)) {
return;
}
}
}
}
如果还实现了删除结点的方法,则要小心 ABA 问题,这时可考虑使用 AtomicStampedReference。
Collections
BlockingQueue
线程级的生产者-消费者问题的实质是分为生产者和消费者的两组线程共享同一个队列,消费者暂不能从队列拉取元素,除非队列非空,生产者暂不能推送元素到队列,除非队列非满。BlockingQueue 既有基于数组的实现,也有基于链表的实现,可用来解决生产者-消费者问题(比如 BlockingQueueDemo),当阻塞队列为空时,线程从阻塞队列拉取元素时会被阻塞或被迫等待,当阻塞队列已满时,线程推送元素到阻塞队列会被阻塞或被迫等待。
LinkedBlockingDeque 和 ArrayBlockingQueue 均使用了 Condition,维护了队列非满条件变量和队列非空条件变量,如下图所示,通知的实现基于上文 “通知” 中提到的 park/unpark。
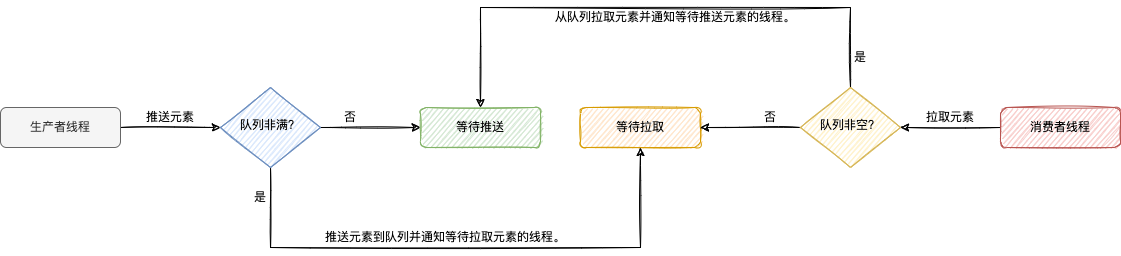
本质上,Condition 实例与 Lock 实例绑定,通过 Lock 实例的 newCondition 方法可新建 Condition 实例。
class BoundedBuffer {
final Lock lock = new ReentrantLock();
final Condition notFull = lock.newCondition();
final Condition notEmpty = lock.newCondition();
final Object[] items = new Object[100];
int putptr, takeptr, count;
public void put(Object x) throws InterruptedException {
lock.lock();
try {
while (count == items.length)
notFull.await();
items[putptr] = x;
if (++putptr == items.length) putptr = 0;
++count;
notEmpty.signal();
} finally {
lock.unlock();
}
}
public Object take() throws InterruptedException {
lock.lock();
try {
while (count == 0)
notEmpty.await();
Object x = items[takeptr];
if (++takeptr == items.length) takeptr = 0;
--count;
notFull.signal();
return x;
} finally {
lock.unlock();
}
}
}
ConcurrentMap
ConcurrentMap 是 Map 的子接口,它定义了有用的原子操作,例如,仅在键存在时才删除或替换键值对,或仅在键不存在时才添加键值对,其中一个标准实现是 ConcurrentHashMap,它是 HashMap 的线程安全版本。
JDK 7 的 HashMap 是基于拉链法的散列表。
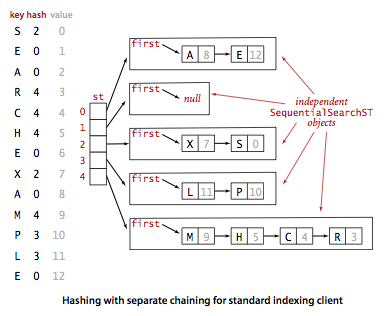
如上面这张来自 algs4 的图所示,散列表是一种符号表(symbol table),符号表是一种存储键值对的数据结构,支持两种操作:
- 插入(put)。查找给定的键是否命中,若命中,则更新对应的值,若未命中,则插入键值对。
- 查找(get)。通过给定的键得到相应的值。
基于拉链法的散列表维护了元素类型是链表的数组,它的查找算法可分为两步:
-
使用 Hash 函数将给定的键转化为数组的索引。
-
在链表中查找给定的键,返回对应的值。
如下面这张来自 Java HashMap internals 的图所示,在 HashMap 中,数组元素称为 bucket 或 bin,链表结点称为 entry。
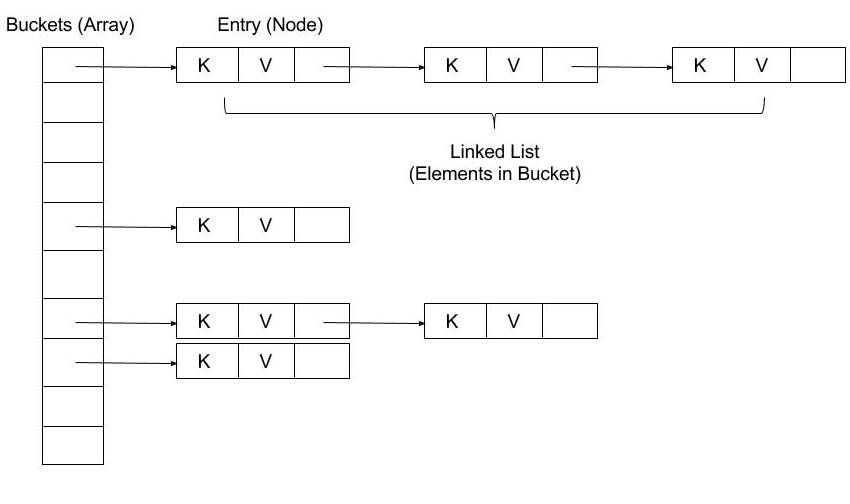
JDK 8 在 HashMap 中引入红黑树以优化查找算法。当一个桶的大小(链表大小)大于等于树化阈值(TREEIFY_THRESHOLD)且桶的数量(数组长度)大于等于 64,该桶将转化为一颗红黑树,当一个桶的大小小于等于解树阈值(TREEIFY_THRESHOLD),该桶将转化为链表。说到红黑二叉查找树,不得不先说二叉查找树和 2-3 查找树,未来将开启 HashMap 的新篇章。
翻阅源码可以知道,例如 ConcurrentHashMap#put 方法,ConcurrentHashMap 使用 CAS 和 synchronized 防止多线程并发访问它维护的链表或红黑树时出现线程干扰和内存一致性错误。
一成不变
如果一个共享对象的状态只读,就不存在线程干扰和内存一致性错误,而且只要尝试改写状态时,每次都新建不同状态的这种对象并返回,完美制造了状态可变的假象(想象一下手翻书),也就不存在线程安全问题。这种对象,被称为不可变对象(Immutable Objects)。定义不可变对象的策略,可参考 A Strategy for Defining Immutable Objects。
《The Joy of Clojure, second-edition》,1.4. Why Clojure isn’t especially object-oriented,作者对不可变的和可变的做了很棒的类比。

后记
单机可以运行数百万个 Go 协程(Goroutine),却只能运行数千个 Java 线程。现在的 Java HotSpot VM,默认一个 Java 线程占有 1 M 的栈(以前是 256K),而且是大小固定的栈,而 Go 协程的栈是大小可变的栈,即随着存储的数据量变化而变化,并且初始值仅为 4 KB。确实,运行过多的 Java 线程容易导致 out of memory,而且 Java 线程与内核线程(原生线程)是 1:1 映射,那么过多线程的上下文切换也会引起应用程序较大延迟;Go 协程与内核线程(原生线程)是多对一映射,Go 实现了自己的协程调度器,实际上要运行数百万个协程,Go 需要做得事情要复杂得多。
若只讨论 Java 单体应用承受高并发的场景,即使扩大线程池也不能显著提高性能或适得其反,相反,少量的线程就能处理更多的连接,比如,Netty。如果仍然认为重量级的 Java 线程是瓶颈,并且还想使用 Java 的话,不妨尝试 Quasar,它是一个提供纤程和类似于 Go 的 Channel 以及类似于 Erlang 的 Actor 的 Java 库。
虽然进程之间不一定共享本机资源,但是线程之间的同步可以推广到进程之间的同步,比如,分布式锁。分布式系统中,代码一致的多个进程可能共享同一个数据库,数据库支持并发控制,比如,共享锁和排他锁以及 MVCC。
文中代码
部分代码已发布,可查看 concurrent。
本文首发于 https://h2cone.github.io/
吸收更多
- 深入理解计算机系统(原书第 3 版)
- Thread (computing)
- ~jbell/CourseNotes/OperatingSystems/4_Threads
- Implementing threads :: Operating systems 2018
- HotSpot Runtime Overview # Thread Management
- JVM 中的线程模型是用户级的么?
- How Java thread maps to OS thread
- HotSpot JVM internal threads
- Java Tutorials # Concurrency # Guarded Blocks
- Thread pool
- Java Tutorials # Concurrency # Thread Pools
- Java Tutorials # Concurrency # Fork/Join
- Fork–join model
- Guide To CompletableFuture
- Java Tutorials # Collections # Streams # Parallelism
- Java Tutorials # Concurrency # Synchronization
- The Java Language Specification, Java SE 8 Edition # Chapter 17. Threads and Locks
- HotSpot Runtime Overview # Synchronization
- OpenJDK Wiki # HotSpot # Synchronization and Object Locking
- The Java Virtual Machine Specification, Java SE 8 Edition # 2.11.10. Synchronization
- The Hotspot Java Virtual Machine by Paul Hohensee
- 【死磕 Java 并发】深入分析 synchronized 的实现原理
- Lock Lock Lock: Enter!
- Inside the Java Virtual Machine by Bill Venners # Thread Synchronization
- Biased Locking in HotSpot
- HotSpotGlossary
- Lock (computer science)
- Mutual exclusion
- Synchronization (computer science)
- Monitor (synchronization)
- Understand the object internally
- 单例模式 - 双重检验锁真的线程安全吗
- Know Thy Java Object Memory Layout
- 【基本功】不可不说的 Java “锁”事
- 码农翻身:用故事给技术加点料
- Java Tutorials # Concurrency # Atomic Access
- Java Tutorials # Concurrency # Atomic Variables
- 聊聊并发 - 原子操作的实现原理
- Java Tutorials # Concurrency
- 唯品会 Java 开发手册 (九) 并发处理
- Why you can have millions of Goroutines but only thousands of Java Threads
- Java中的纤程库 - Quasar
- 继续了解 Java 的纤程库 - Quasar
- The actor model in 10 minutes - Brian Storti