分布式缓存
铺垫
存储层次结构
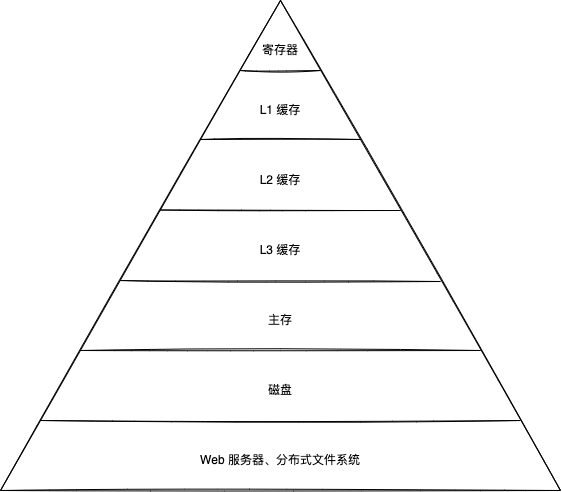
- 自下而上,更小更快。
- 自顶向下,更大更慢。
- 上层是下层的(高速)缓存。
软件系统三大目标
| 目标 | 解释 | 期望 | 战术 |
|---|---|---|---|
| 可靠性 | 容错能力 | 硬件故障、软件错误、人为失误发生时继续正常运作 | 熔断、降级、自动恢复、容灾、高可用、强一致性…… |
| 可扩展性 | 应对负载增加的能力 | 负载增加时保持良好性能或高性能 | 低延迟、高吞吐、弹性伸缩…… |
| 可维护性 | 运维和开发的难易程度 | 既简单又好拓展 | DRY、SoC、DevOps…… |
Redis cluster
单一独立的 Redis 结点,虽然它真的很快(未来将开新篇章解释),但是也有上限,性能提升总将遇到天花板,而且单点故障将导致一段时间服务不可用。
Redis 集群如何解决可靠性问题和扩展性问题?
- 数据在多个 Redis 结点之间自动分片(shard)。
- Redis 集群可以在分区期间提供一定程度的可用性(availability)。
- 水平扩展 Redis(scalability)。
数据分片
Redis 集群不使用一致性哈希,而是使用哈希槽(hash slot)。
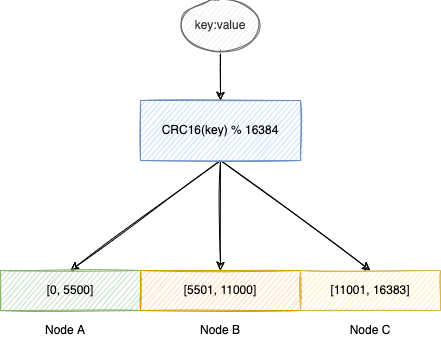
如上图所示,Redis 集群中的结点(node)负责各自的哈希槽。向集群插入一个键(key)时,只是计算给定键的 CRC16 并取 16384 的模来将给定键映射到哈希槽。
使用哈希槽可以“轻松”在集群中添加结点到删除结点。若增加一个结点 D,则从 A、B、C 移动一些哈希槽到 D,同理,若删除一个结点 A,则从 A 移动哈希槽到结点 B、C、D,当 A 为空可被完全从集群移除;而且,添加结点、删除结点、更改结点的哈希槽的百分比都不要求集群暂停运作,不需要任何停机时间。
值得注意的是,Redis 集群支持多个键的操作,前提是单个命令执行或整个事务或 Lua 脚本执行中涉及的所有键属于同一个哈希槽。我们可以使用称为 hash tags 的概念来强制多个 key 映射到同一个哈希槽。
可用性与一致性
Redis 集群使用主从模型(master-slave model) 实现故障转移。

如上图所示,在集群创建时或稍后,我们给每个主结点添加从结点,例如 B 是主结点,B1 是它的从结点,B1 的哈希槽是 B 的哈希槽的副本。当 B 发生故障,集群将提升 B1 为新主结点,继续提供服务;以此类推,当有若干主结点发生故障时,它们的从结点将替代它们成为新主结点,以此提供一定程度的可用性。
为什说是一定程度的可用性,考虑以下的场景,集群极可能不能正常运作。
- 一对主从结点同时故障。
- 超过半数的结点发生了故障。
Redis 集群无法保证强一致性(strong consistency)。Kafka 的作者 Jay Kreps 曾经说过:
Is it better to be alive and wrong or right and dead?
在可用性与一致性天平之间,Redis 集群侧重于可用性。当一个客户端连接集群并写入键,丢失写(lose writes)可能发生,因为 Redis 使用异步复制(asynchronous replication)。
-
客户端将给定键写入主结点 B
-
主结点 B 发送 OK 给客户端
-
从 B 复制数据到从结点 B1、B2、B3……
注意,上面操作 2 和操作 3 非阻塞,即客户端写的同时,主结点 B 执行数据复制任务(通常只需复制命令),而不是阻塞直到所有数据复制完成再回复客户端,数据复制必定存在滞后;当 B 发生故障停止复制且 B 的从结点提升为新主结点,新主结点将可能不存在客户端已写入的键。
这也是一种在性能与一致性之间的权衡(trade-off)。
即使 Redis 支持同步复制,也有其它更复杂的情景导致主结点与从结点数据不一致。一种情景是从结点提升为主结点时,客户端将可能找不到目标键或读取了脏数据;当客户端发送一次足够大的键或足够多的键到一个主结点,以至于该主结点的从结点有充分时间提升为新主结点,旧主结点将拒绝接受键,且新主结点不存在客户端写入的键。
未来将开新篇章谈谈分布系统的一致性和可用性。
最小的集群
从 antirez/redis 克隆。
git clone -v https://github.com/antirez/redis.git
编译一下。
cd redis
make
编译成功后,可以使用名为 redis-server 的可执行文件启动单 Redis 实例。
cd src
./redis-server
检查 utils/create-cluster 目录,可以发现一个名为 create-cluster 的 Shell 脚本,该脚本基于 Redis 集群创建和管理命令行工具:
redis-cli --cluster
创建 Redis 集群需要先启动若干 Redis 实例。
create-cluster start
create-cluster create
截取以上脚本输出的一部分:
M: 02f543ee55bb36c72816617d24aaf3c1438abdd1 127.0.0.1:30001
slots:[0-5460] (5461 slots) master
1 additional replica(s)
S: c7dcf3932a10ea80cd67e1f350c328b272da1cf4 127.0.0.1:30006
slots: (0 slots) slave
replicates 6b27d42f51f5991f2458be0bf48bc28691e71dd4
M: 6b27d42f51f5991f2458be0bf48bc28691e71dd4 127.0.0.1:30003
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
M: cf89f789b2347d73e91f035d0c6b3b5eef0d8414 127.0.0.1:30002
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: 0b6d6ade090167e47bb74d385548c6b787d52f71 127.0.0.1:30005
slots: (0 slots) slave
replicates cf89f789b2347d73e91f035d0c6b3b5eef0d8414
S: 0166962044b5fa13cf64d0c968963e5ee63f3241 127.0.0.1:30004
slots: (0 slots) slave
replicates 02f543ee55bb36c72816617d24aaf3c1438abdd1
默认情况下,总共 6 个结点,3 个 主结点(M),3 个 从结点(S),更多用法请参考 utils/create-cluster/README。
我们使用 redis-cli 试验一下自动数据分片。
% redis-cli -c -p 30001
127.0.0.1:30001> set foo bar
-> Redirected to slot [12182] located at 127.0.0.1:30003
OK
% redis-cli -c -p 30003
127.0.0.1:30003> set hello world
-> Redirected to slot [866] located at 127.0.0.1:30001
OK
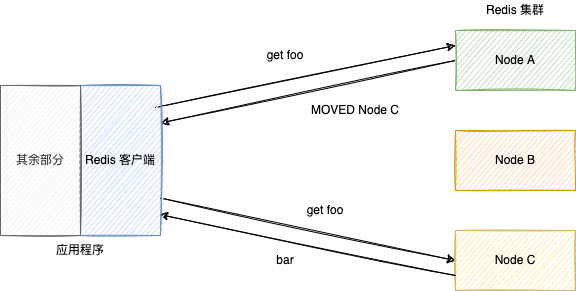
当查找键时,可能返回错误信息,提示我们转而连接其它结点。
% redis-cli -p 30002
127.0.0.1:30002> get foo
(error) MOVED 12182 127.0.0.1:30003
redis-cli -p 30003
127.0.0.1:30003> get foo
"bar"
当然,redis-cli 支持重定向。
% redis-cli -c -p 30002
127.0.0.1:30002> get foo
-> Redirected to slot [12182] located at 127.0.0.1:30003
"bar"
127.0.0.1:30003> get hello
-> Redirected to slot [866] located at 127.0.0.1:30001
"world"
访问 Redis 集群的应用程序无法直接使用命令行工具,应用程序的 Redis 客户端需要以 Redis 集群的协议与 Redis 实例通信。在 Java 生态中,Jedis 已支持 Redis 集群。
Set<HostAndPort> jedisClusterNodes = new HashSet<HostAndPort>();
//Jedis Cluster will attempt to discover cluster nodes automatically
jedisClusterNodes.add(new HostAndPort("127.0.0.1", 7379));
JedisCluster jc = new JedisCluster(jedisClusterNodes);
jc.set("foo", "bar");
String value = jc.get("foo");
客户端路由
一个严肃的客户端除了实现重定向或路由,还应该缓存哈希槽与结点地址之间的映射(进程内缓存或本地缓存),直接连接正确的结点(减小重定向频率)。发生故障转移之后或系统管理员增加或删除结点之后,客户端需要刷新映射。
代理分发
客户端与一群 Redis 实例交流能否简化成与单一 Redis 实例交流?答案是增加一个中间层。
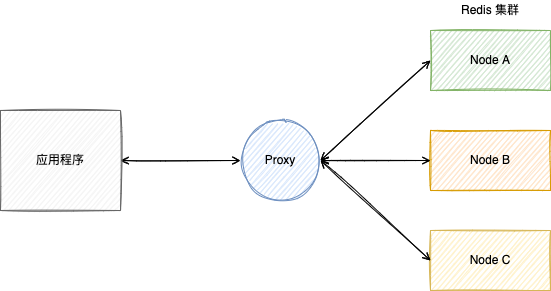
代理(Proxy),比如 Redis Cluster Proxy 和 CodisLabs/codis,但是,代理通常也要提供一定程度的可用性。
容器化
为了使 Docker 与 Redis 集群兼容,需要使用 Docker 的 host networking mode,详情请见 docker # network。
组合拳
在高负载下的分布式系统中,我们通常考虑使用 Redis 作为 MySQL 等关系型数据库的(高速)缓存,虽然应用程序都要与它们通信,但是 Redis 访问内存要比数据库访问磁盘快得多,转而解决开头所说的三大问题;但仍然不是最优方案,再如开头所说,我们可以利用更上层的(高速)缓存,应用程序与 Redis 集群的网络开销可以通过进程内缓存或本地缓存进一步降低。
例如,J2Cache,它将 Java 进程缓存框架作为一级缓存(比如 Ehcache),将 Redis 作为二级缓存。查找键时,先查找一级缓存,若一级缓存未命中则查找二级缓存。那么它如何解决一致性问题和可靠性问题?
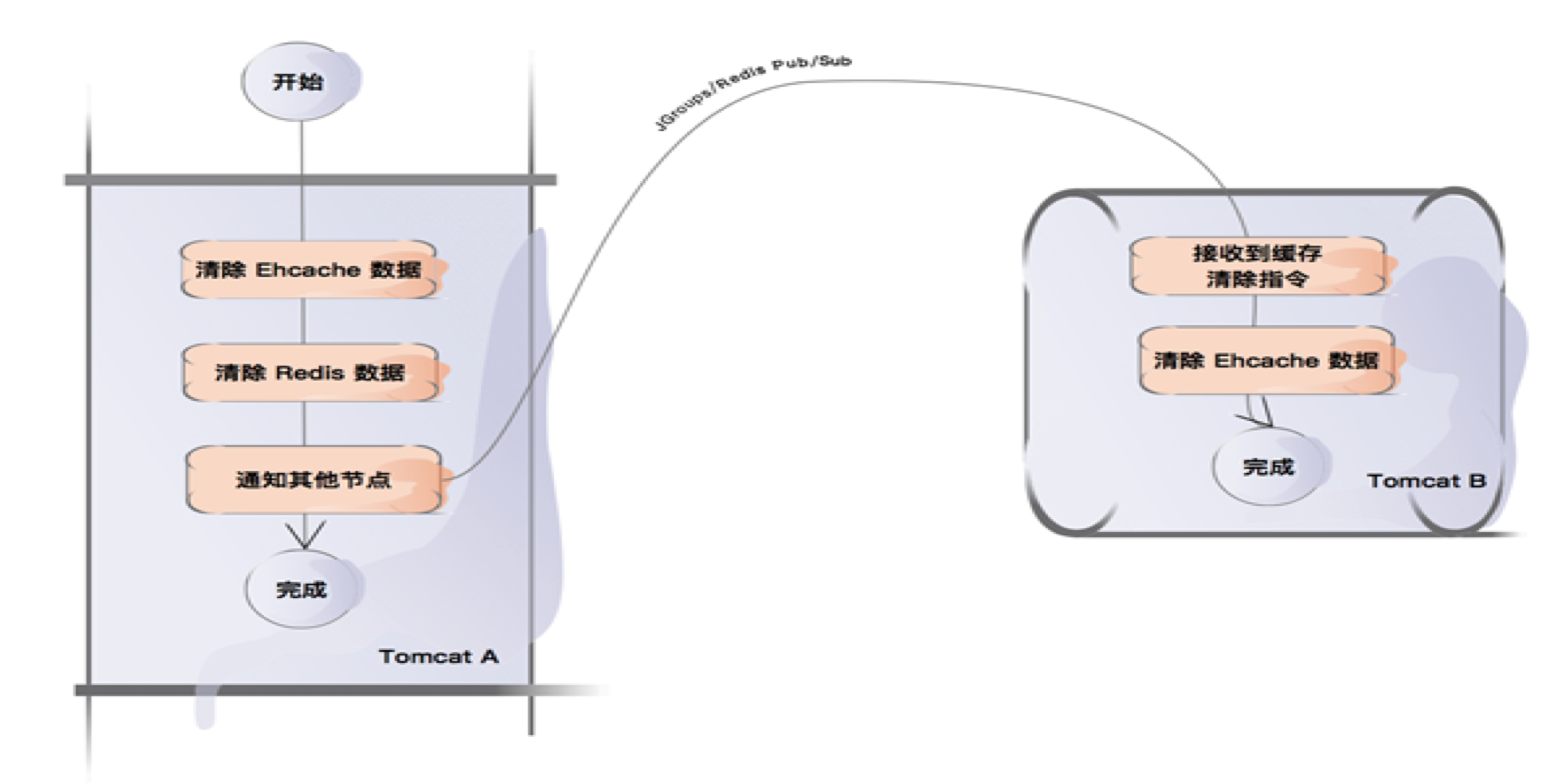
它可以使用 Redis 的发布/订阅(类似消息中间件的特性)来保证多个应用程序实例之间一定程度的缓存一致性,一定程度是因为 Redis 官方说将来有计划支持更可靠的消息传递;所谓可靠的消息传递,类比 TCP 可靠传输的基本思想,即确认、超时、重传等概念。
CDN
Content delivery network,即内容分发网络,不容忽视的大规模分布式多级缓存系统。
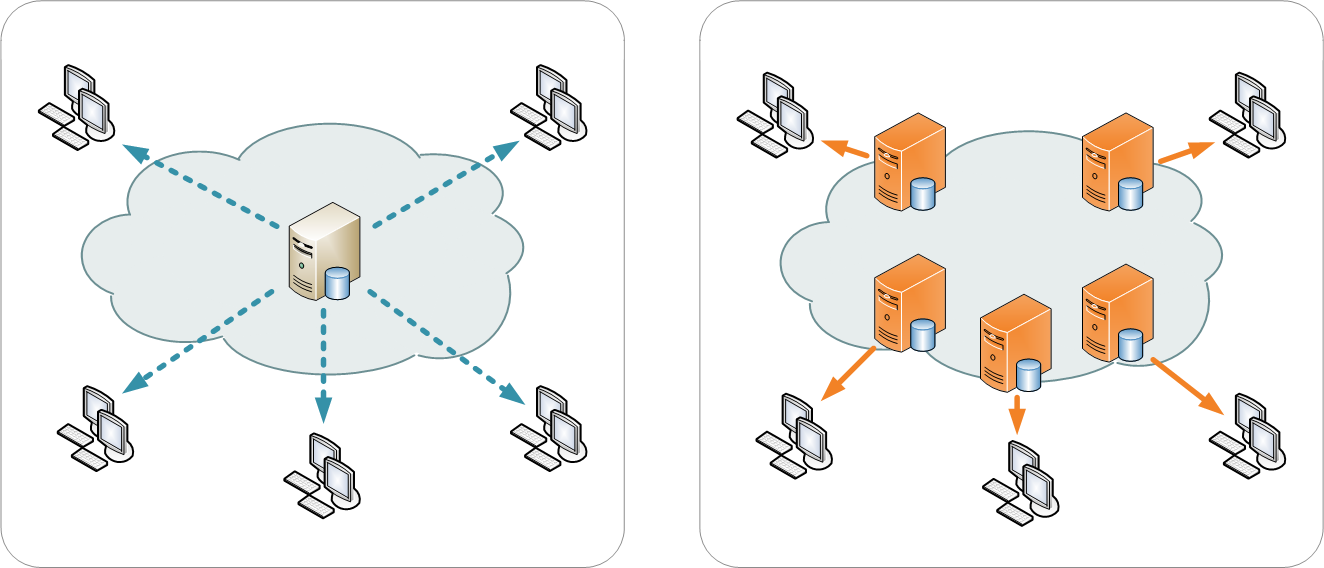
如上面这张来自维基百科的插图所示,左手边是单服务器分发,右手边是 CDN 分发。CDN 结点通常部署在多个位置,CDN 系统能够在算法上将浏览器的请求导向离用户最近或最佳的 CDN 结点,浏览器则配合系统就近访问结点。使用 CDN 至少具有如下优势:
- 降低带宽成本。
- 缩短响应时间。
- 提高内容的的全球性。
CDN 系统是(回)源主机及其 Web 服务器的(高速)缓存,CDN 系统适合缓存的内容是文件。
本文首发于 https://h2cone.github.io/