从 MySQL 到 TiDB
MySQL 窘境
扩展
数据以前所未有的速度增长,例如从 GB 到 TB,甚至到 PB;负载增加,例如单位时间请求数、I/O 次数、活跃用户数激增;这可能引起单机 MySQL server 性能下降,甚至不可用。我们想尽办法扩展 MySQL,通常,要么采购更强大的机器作为数据库服务器,这是一种纵向扩展(scale up);要么对 MySQL 的库或表进行分片(MySQL Sharding),即将数据集分离得到多个子数据集,任意两个子数据集可能存储在同一台机器上,也可能存储在不同机器上,这是一种横向扩展(scale out)。
纵向扩展需要应对一些问题:
- 成本增长过快。如果把一台机器的 CPU 核数增加一倍,主存和磁盘各扩容一倍,则最终总成本增加不止一倍。
- 预见性能瓶颈。一台机器尽管拥有两倍的硬件指标但却不一定能处理两倍的负载。
- 有限容错能力。显然无法提供异地容错能力。
横向扩展一般不需要高端的硬件或机器,但需要多台一般的机器和应对分布式系统的许多挑战:
- 故障与部分失效。
- 不可靠的网络。
- 不可靠的时钟。
因为关心系统应对负载增加的能力(可扩展性),所以关心系统容错能力(可用性与一致性)。
达成以上目标至少需要分区,对于 Elasticsearch 和 SolrCloud 以及 MongoDB 来说是 shard;对于 Cassandra 和 HBase 分别是 vnode 和 region。
为什么分区
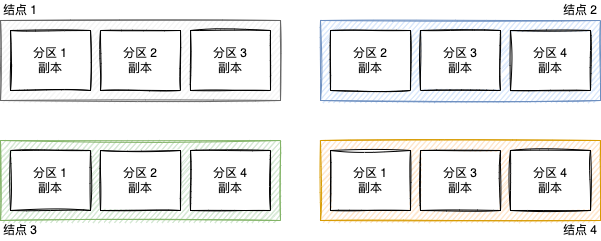
副本的优势:
- 容错。容忍结点失效,支持故障转移。
- 横向扩展。采用多结点来处理更多的请求。
- 就近访问。将副本部署到距离用户更近的地方。
Partitioning
项目开始初期,什么情况下适合对 MySQL 分库分表?阿里巴巴 Java 开发手册在“MySQL 数据库“章节中有一则推荐,仅供参考:
【推荐】单表行数超过 500 万行或者单表容量超过 2 GB,才推荐进行分库分表。 说明:如果预计三年后的数据量根本达不到这个级别,请不要在创建表时就分库分表。
我们通常使用垂直分区(vertical partitioning)和水平分区(horizontal partitioning),如下图所示:
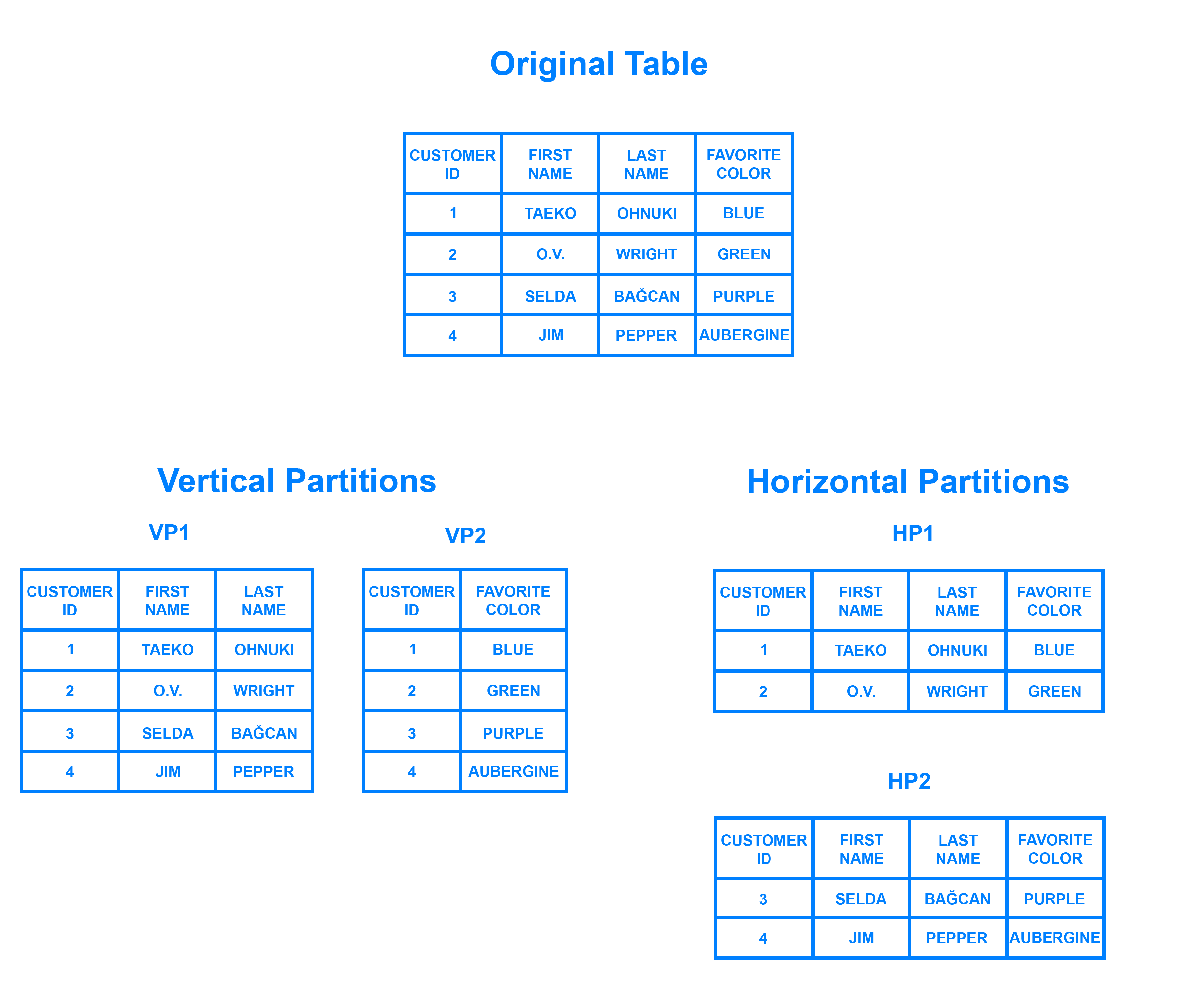
VP1 和 VP2 表现得像两张可通过 ID 关联起来的表,HP1 和 HP2 的 scheme 和列(columns)相同,但行(rows)不同。行的增长速度通常快于列的增长速度,我们更关注水平分区,数据库分片是数据库或搜索引擎的水平分区;但新问题随之而来:假设 HP1、HP2、HP3、HP4…… 包含了多张表的数据,且由多个 MySQL server 维护,如果客户端要查找满足给定条件的一行或多行记录,那么它应该向哪个或哪些 MySQL server 发起请求?如何合并多个结点返回的结果集?如何执行跨分区 JOIN、排序、分页、分组等操作?如何保证分布式事务?
在以前,上面问题的解决方案常常是数据库中间件,数据库中间件的设计模式至少有两种,Proxy 和 Smart Client。Proxy 是应用程序与数据库集群的中间层,它对客户端制造了单一数据库实例的假象,客户端发送到 Proxy 的请求将由 Proxy 分发给下层的数据库服务器;Smart Client 是与应用程序集成的库或框架,客户端向数据库集群发起的请求将由客户端路由。两者的图像可参考代理分发和客户端路由。
目前,开源且较活跃的数据库中间件有 ShardingSphere、MyCAT、vitess 等等,一直以来勉强可用,但是前两者的缺点也不容忽视:
- 侵入性。要求用户指定 shard key 和其它分片配置;如果原业务逻辑包含 JOIN、subquery 等复杂 SQL,改动工作量可能难以估计。
- 不支持透明分片。维护分片或集群的代价随着结点的增多而非线性增长。
- 暂不支持弹性伸缩。据说都还在开发中。
- 复杂查询优化能力较弱。不能生成最优的执行计划(plan),许多优化工作推卸给应用程序。
如何将原始表(orginal table)的记录分配给多个 MySQL server(实例、进程)?数据库中间件是应用程序级别的实现,MySQL Cluster 则是数据库级别的实现,它声称支持跨结点自动分片(分区),可是它是通过 NDB 存储引擎实现的,不温不火。
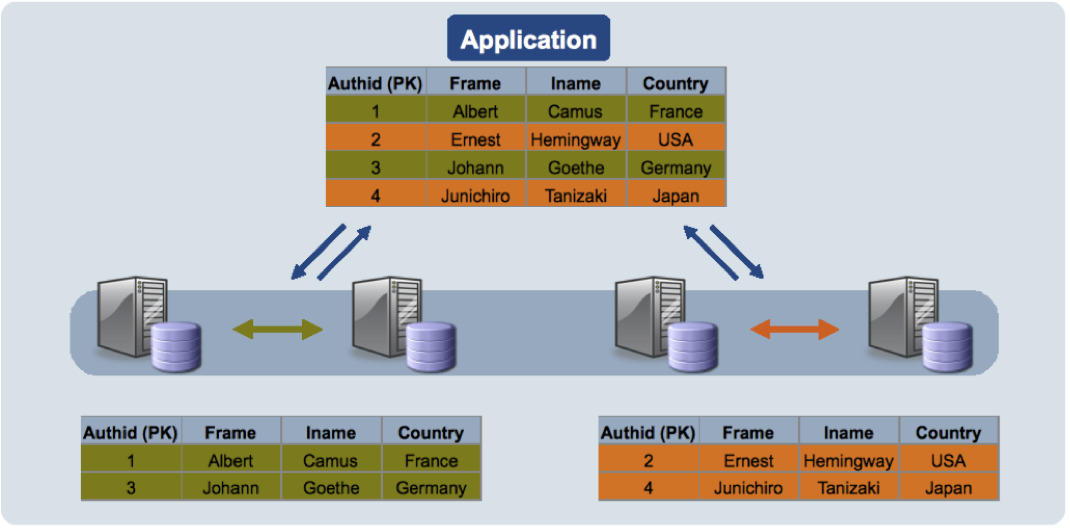
主从复制
MySQL 的数据复制模型是主从复制。传统主从复制图像:主结点(主副本、主库)处理读/写请求,若是写请求则通过同步复制或异步复制将数据变更日志(事件或日志记录)发送到所有从结点(从副本、从库),从结点按照日志(日志记录或事件)写副本;一般情况,从结点只读,故障转移时从结点可提升为主结点。传统的同步复制侧重一致性,要求”短暂“的不可用,主结点需要等待从结点的确认;传统的异步复制侧重可用性,要求“短暂”的不一致,从结点滞后于主结点。
如果把所有从结点配置为同步复制模式,那么任何失效或性能下降的从结点会导致系统阻塞。MySQL 支持设置半同步模式,某一个从结点配置为同步模式,其它从结点配置为异步模式;当同步模式的从结点失效时,另一个从结点从异步模式提升为同步模式,这么做的好处之一是保证至少有两个结点(主结点和同步模式的从结点)拥有最新的数据副本。半同步并非高枕无忧,微信后台团队在 MySQL 半同步复制的数据一致性探讨中总结了 MySQL 的半同步复制和 Master 切换都存在一些不足,数据复制存在回滚难题,Master 切换存在多 Master 难题。
主从复制模型不能保证同时满足强一致性和高可用性。如果出现结点失效、网络中断、延迟抖动等情况,多主结点复制方案会更加可靠,但是代价则是系统的高复杂度和弱一致性保证。多主结点复制适用于多数据中心,每个数据中心采用常规的主从复制方案,各个数据中心的主结点负责与其它数据中心的主结点交换 replicated log。
小结
面对透明分片(transparent sharding)、弹性伸缩(auto-scaling)、自动恢复(auto-failover)、**异地多活(multi-data center)~**等需求,传统的解决方案使我们陷入窘境。
SQL 和 NoSQL
ACID 和 BASE
为什么不使用 NoSQL 数据库代替 MySQL 数据库呢?假设我们有了大刀阔斧迁移数据和重写应用程序的决心(基本不可能),但是许多 NoSQL 数据库都牺牲了一致性,而倾向于可用性,这种一致性模型往往被称为 BASE:
- 基本可用性(Basically Available)。
- 软状态(Soft state)。类似中间状态。
- 最终一致性(Eventual consistency)。
BASE 模凌两可,太长或永远不一致的系统基本不可用。许多处理重要数据的系统(例如,财务、订单、互联网金融系统等)随着快速增长的数据和负载,常规的关系数据库扩展困难,而对于 ACID ,特别是一致性的要求,NoSQL 数据库难以满足。相较于 BASE 的承诺,关系数据库的 ACID 的承诺是五十步笑百步(一致性往往推卸给应用程序):
- 原子性(Atomicity)。事务中的操作序列,要么全部执行成功(提交),要么全部不执行(回滚)。
- 一致性(Consistency)。不蕴含矛盾,逻辑自洽……
- 隔离性(Isolation)。同时运行的事务不应相互干扰,事务提交时,其结果与串行执行完全相同。
- 持久性(Durability)。无完美或绝对的保证。
数据模型与查询语言
NoSQL 数据库缺乏 JOIN 的能力,这是其文档模型的限制。关系数据库市场占有率一直居高不下,参考 DB-Engines Ranking,原因之一是 SQL(DDL、DML、DQL、DCL) 是声明式语言的代表,它的简单与统一在于指定结果所满足的模式,在不改变语句的前提下,查询优化器或底层引擎的迭代更新就有可能显著提高性能。
SQL 的关系模型理论足够优雅:
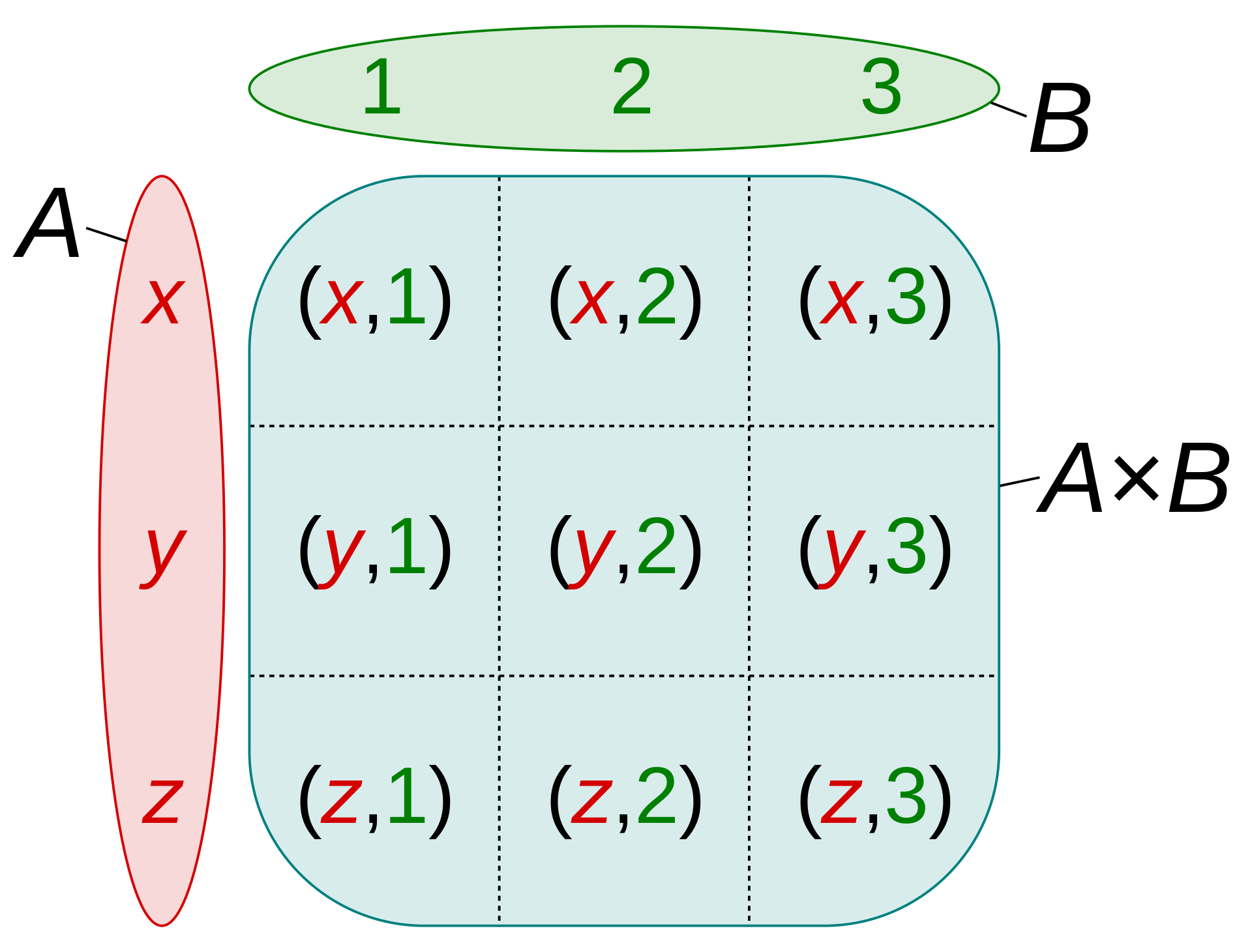
近年来,流行开源组件提供类 SQL 的趋势越来越明显,例如 Spark SQL、KSQL、Flink SQL、ClickHouse SQL…
NewSQL 新在哪
NewSQL 是一类关系数据库系统,旨在为 OLTP 提供 NoSQL 数据库系统的可扩展性,同时提供传统关系数据库系统的 ACID 保证。OLTP 与 OLAP 有时区分并不是那么明显,前者侧重 T(事务),后者侧重 A(分析):

NewSQL 数据库系统新在架构、存储引擎、共识算法。
你好 TiDB
TiDB 项目受到了 Spanner/F1 与 Raft 的启发,TiKV 对应的是 Spanner,TiDB 对应的是 F1,详情请看 TiDB 整体架构、TiDB 数据库的存储、TiDB 数据库的计算、调度概述……
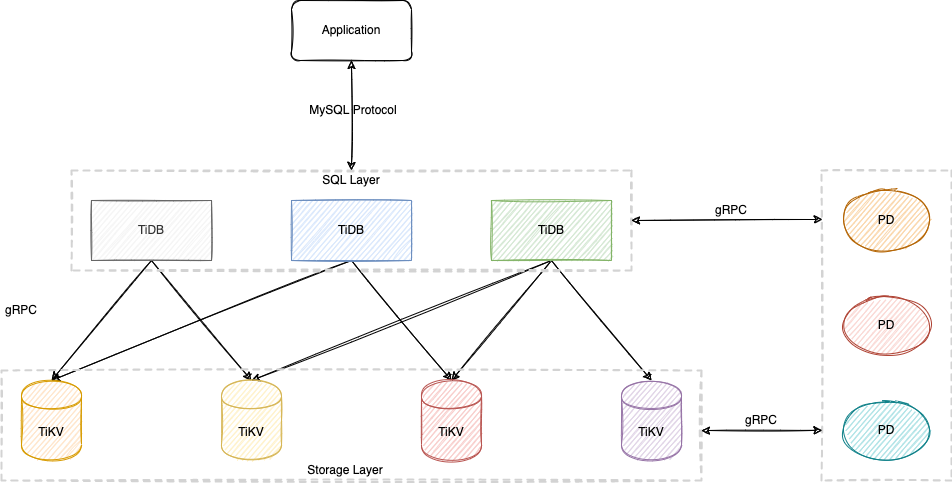
SQL Layer 无状态,可以通过负载均衡组件(如 LVS、HAProxy、F5)对外提供统一的接入地址。
tiup playground v4.0.0 --db 3 --kv 4 --pd 3 --monitor
如上所示,使用 tiup 启动了 3 个 TiDB 实例和 4 个 TiKV 实例以及 3 个 PD 实例。
Waiting for tikv 127.0.0.1:20160 ready
Waiting for tikv 127.0.0.1:20161 ready
Waiting for tikv 127.0.0.1:20162 ready
Waiting for tikv 127.0.0.1:20163 ready
CLUSTER START SUCCESSFULLY, Enjoy it ^-^
To connect TiDB: mysql --host 127.0.0.1 --port 4000 -u root
To connect TiDB: mysql --host 127.0.0.1 --port 4001 -u root
To connect TiDB: mysql --host 127.0.0.1 --port 4002 -u root
To view the dashboard: http://127.0.0.1:2379/dashboard
To view the monitor: http://127.0.0.1:9090
TiDB 非常友好地兼容了 MySQL 5.7 协议,从 MySQL 迁移到 TiDB 对应用程序无限接近零侵入。这里我们可以通过 MySQL 命令行工具连接某一个 TiDB 实例。
% mysql --host 127.0.0.1 --port 4000 -u root
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 5
Server version: 5.7.25-TiDB-v4.0.0 TiDB Server (Apache License 2.0) Community Edition, MySQL 5.7 compatible
Copyright (c) 2000, 2020, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| INFORMATION_SCHEMA |
| METRICS_SCHEMA |
| PERFORMANCE_SCHEMA |
| mysql |
| test |
+--------------------+
5 rows in set (0.00 sec)
导入样本数据集到某一个 TiDB 实例,样本数据集的 database 名称为 employees。
% mysql --host 127.0.0.1 --port 4001 -u root < employees.sql
INFO
CREATING DATABASE STRUCTURE
INFO
storage engine: InnoDB
INFO
LOADING departments
INFO
LOADING employees
INFO
LOADING dept_emp
INFO
LOADING dept_manager
INFO
LOADING titles
INFO
LOADING salaries
data_load_time_diff
NULL
我们会发现,连接任意一个 TiDB 实例都能观察到 employees 库。
mysql> show tables from employees;
+----------------------+
| Tables_in_employees |
+----------------------+
| current_dept_emp |
| departments |
| dept_emp |
| dept_emp_latest_date |
| dept_manager |
| employees |
| salaries |
| titles |
+----------------------+
8 rows in set (0.00 sec)
TiKV 数据分区的术语是 Region,使用 Raft 对写入数据在多个 TiKV 结点(实例)之间自动分片和复制日志,每个 Region 的所有副本(默认为三副本)组成一个 Raft Group,每个 TiKV 实例(结点)负责多个 Region。
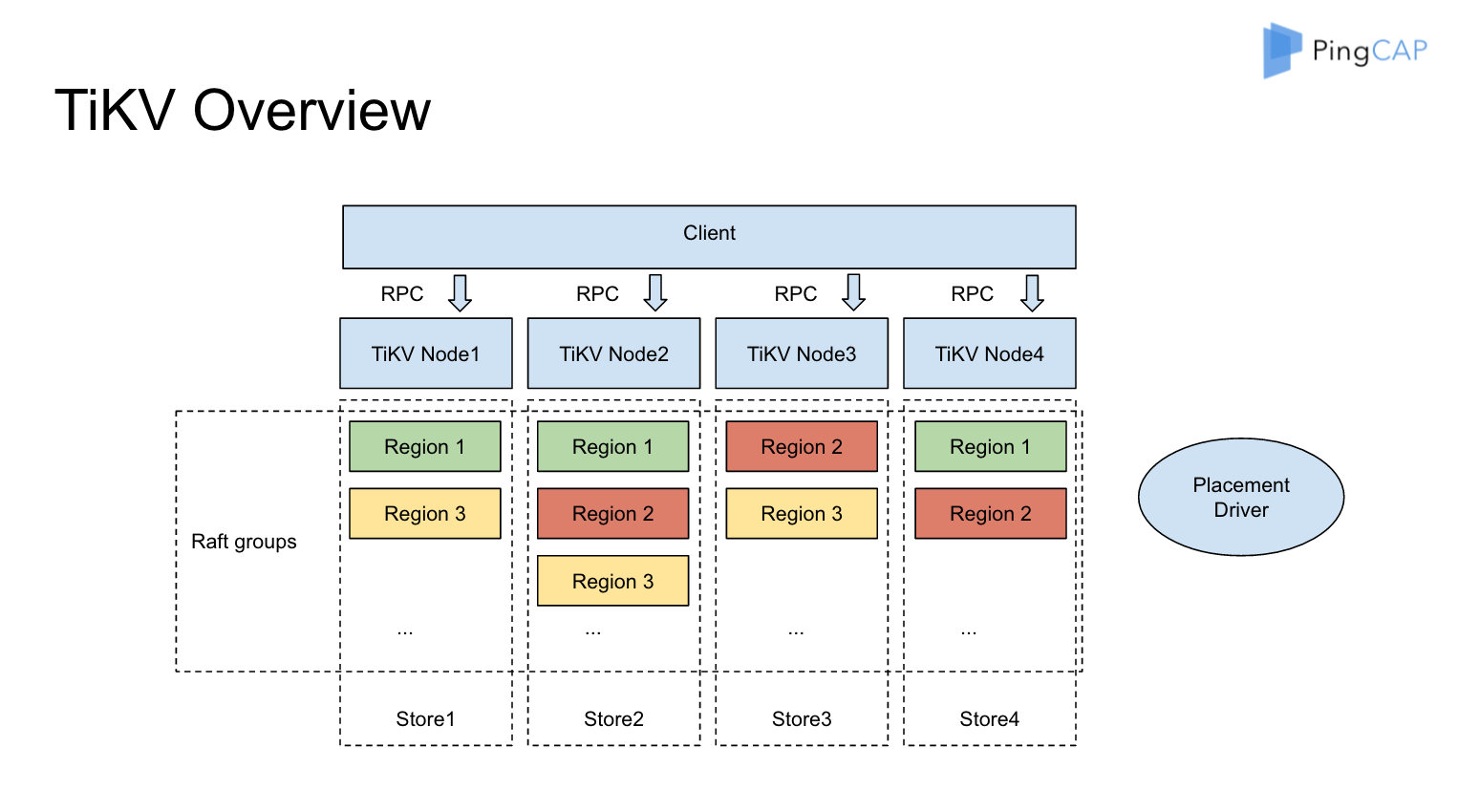
同城多数据中心部署和两地三中心部署则提供了更强大的容错(容灾)能力。
本文首发于 https://h2cone.github.io/
参考资料
- Designing Data-Intensive Applications
- Understanding Database Sharding
- “分库分表" ?选型和流程要慎重,否则会失控
- MySQL 5.7 Reference Manual # Replication Implementation
- SQL vs NoSQL: What’s the difference?
- Wiki # NewSQL
- Shared-nothing architecture
- 演讲实录|黄东旭:分布式数据库模式与反模式
- How do we build TiDB
- PingCAP blog
- TiDB 数据库快速上手指南
- PingCAP docs