日志游记
什么是日志
日志是追加式的,按时间排序的记录(条目)序列。
.png)
无关记录的格式,日志文件记录操作系统或其它软件运行时发生的事件及其时间。
<34>1 2003-10-11T22:14:15.003Z mymachine.example.com su - ID47 - BOM'su root' failed for lonvick on /dev/pts/8
“应用程序日志”是人类可读的文本,比如 Syslog 和 SLF4J 等;如上所示,这是一个来自 RFC5424 的 syslog 日志消息例子,从中不难看出主机(mymachine.example.com)上的一个应用程序(su)在 2003-10-11T22:14:15.003Z 发生了 “‘su root’ failed for lonvick…”。
现代最流行的分布式版本控制系统中的日志记录着所有贡献者的提交历史:
% git log
...
commit 130560a769fe6da64c87f695e4665225de1faec3
Author: Daniel Smith <dbsmith@google.com>
Date: Fri Jun 6 17:31:45 2014 -0700
Proofread guestbook.md
commit 2c4b3a562ce34cddc3f8218a2c4d11c7310e6d56
Author: Joe Beda <joe.github@bedafamily.com>
Date: Fri Jun 6 16:40:48 2014 -0700
First commit
然而,日志并非全都是人类可读的,它可能是二进制格式而只能被程序读取,作为关键抽象普遍存在于数据库系统和分布式系统之中。
数据库日志
关系数据库系统中的日志通常用于崩溃恢复、提供一定程度的原子性与持久性、数据复制。
预写日志
根据经验,我们确信入库数据终将会被写入磁盘。磁盘是一种 I/O 设备(参考网络·NIO # I/O),从主存复制数据到 I/O 设备并不是一个原子操作,如果客户端发送请求后,数据库服务端处理请求中,系统崩溃或宕机抑或重启,服务端·如何保证不丢失变更或者恢复到正确的数据?
很久以前,存在着无原子性的非分布式数据库事务。张三账户有 1000 元,李四账户有 2000 元,张三向李四转账 200 元,数据库系统先将张三账户减少 200 元,然后将 800 元写回张三账户,接着将李四账户增加 200 元并且将 2200 元写回李四账户时,服务器突然发生故障;系统重启后,只有一个账户是对的,张三账户是 800 元,但是李四账户还是 2000 元,200 元不翼而飞。
计算机界明显的坑早已被前人填满。Write-ahead logging 是数据库系统中提供原子性与持久性的技术(日志先行技术),简称 WAL,一言蔽之,数据库系统首先将数据变更记录到日志中,然后将日志写入稳定存储(如磁盘),之后才将变更写入数据库。
Redo log 和 Undo log 是运用了 WAL 的磁盘数据结构:
- Undo log 在崩溃恢复期间用于撤消或回滚未提交的事务。
- Redo log 在崩溃恢复期间用于重做已提交但未将数据库对象从缓冲区刷入磁盘的事务。
撤消和重做的前提是记录了数据库对象变更前的值和变更后的值。
假设事务 T(i) 所操作的数据库对象是 X,X 的值从 V(old) 更改为 V(new),将数据从缓冲区刷入磁盘的操作被称为 flush,那么 undo/redo log 日志记录形式如下:
begin T(i) //(1)
(T(i), X, V) //(2)
commit T(i) //(3)
(1)记录事务开始。
(2)记录数据库对象的值。Undo log 记录 (T(i), X, V(old)) ,而 Redo log 记录 (T(i), X, V(new)),两者都要求 flush X 之前 flush (T(i), X, V)。
(3)记录事务提交。Undo log 要求 flush X 之后 flush (commit T(i)),而 Redo log 要求 flush X 之前 flush (commit T(i))。
在崩溃恢复期间,从数据库系统角度来看:
- 若发现 undo log 缺少(3),则无法确定 flush X 是否完成。决定将 X 的值设为 V(old) 后 flush X,因为 X 变更前的值是 V(old),即使恢复过程中又发生崩溃,重复将 X 的值设为 V(old) 仍然幂等,直到恢复完成后,可以在(3)位置写一条记录:rollback T(i),下次恢复期间忽略。
- 若发现 redo log 缺少(3),则确定 flush X 未执行。决定将 X 的值设为 V(new),重试 flush X。
- 若发现缺少(2),则忽略此事务(无计可施)。
- 若没有(1),则无此事务。
逻辑日志
前文MySQL 窘境 # 主从复制中提到其数据复制需要数据变更日志,或则数据变更日志记录(事件)。MySQL Server 有若干种日志,其中二进制日志(Binary log,简称 binlog)包含描述数据变更的“事件”,例如创建表或对表数据的更改,MySQL binlog 与存储引擎解耦。
在服务化架构中,组合使用 MySQL 和 Elasticsearch 时常常要求将 MySQL 数据同步到 Elasticsearch;Elastic Stack 的解决方案是使用 Logstash 的插件:Jdbc input plugin。
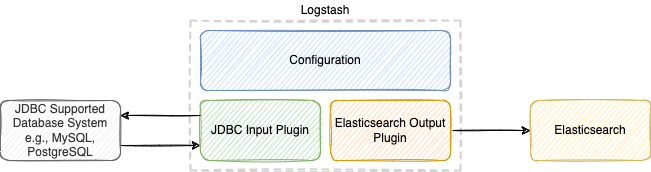
Logstash 的 Jdbc input plugin 会根据配置文件定时/定期对 MySQL 进行轮询,可获取上一次询问之后插入或更改的记录。有人误以为 Jdbc input plugin 最快只能每分钟查询一次,实际上也能设置秒级。
监听 binlog 事件可以实现将 MySQL 数据同步到各种数据源,这种方案非常适合各种消息传递、数据流、实时数据处理。假设有一个中间件,根据 MySQL 协议,它只要向 MySQL master 注册为 MySQL slave,持续接收并解析 binlog 事件,经过处理后又能作为消息传递给各种服务或组件以满足数据同步需求;比如 alibaba/canal,它是一个关于 MySQL binlog 增量订阅&消费的组件。
诸如此类的设计模式被称为 CDC(change data capture)。
分布式系统日志
这要从状态机复制说起。如下图所示,每个 Server 存储了一个它的状态机(State Machine)按顺序执行的一系列命令的日志(Log);每个日志包含相同顺序的命令集,因此每个状态机将执行相同的命令序列;因为讨论的状态机具有确定性,所以它们将产生相同的输出并以相同的状态结束。
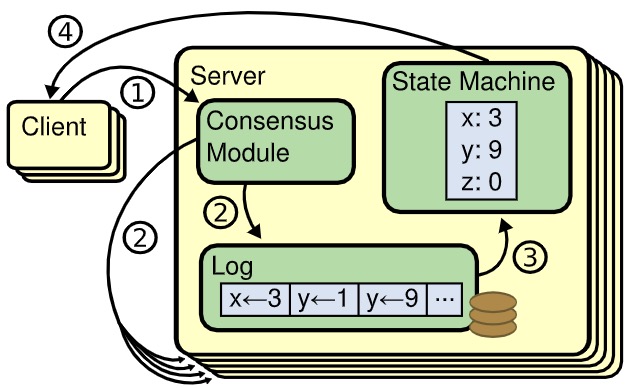
什么是确定性?给定特定的输入,将始终产生相同的输出。作为反面,执行类似以下命令的若干状态机(进程)将产生不同的输出并以不同的状态(磁盘和主存中的数据)结束。
INSERT INTO t VALUES (NOW());
状态机复制通常使用 replicated log 实现,保持 replicated log 的一致性是共识算法的工作。
提交日志
Apache Kafka 分区(partition)的本质是提交日志(commit log)。
如果把 Kafka 与关系型数据库作类比,那么消息(message)类比行(row),主题(topic)类比表(table);一个主题分成多个分区,分区是追加式的消息序列,同一个主题的多个分区可以分布在不同机器上。
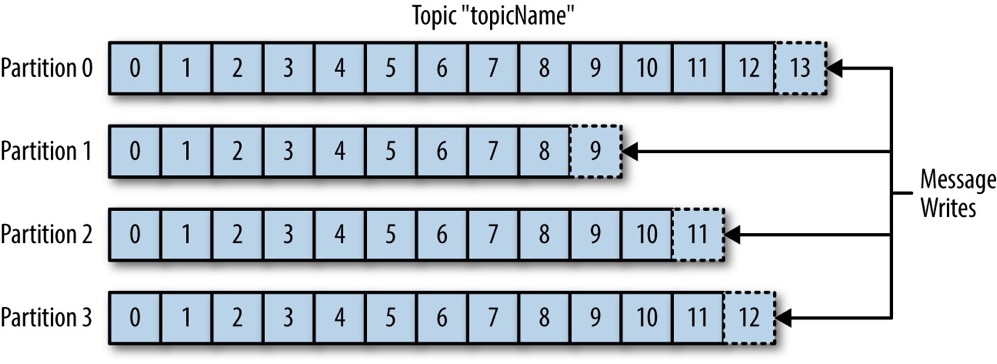
从 Kafka 的角度来看,将消息写入分区就像将日志记录写入提交日志(追加式更新日志文件)。
在 Kafka 的 server.properties 中,有一个 log.dirs 用于指定日志文件目录列表。
# A comma separated list of directories under which to store log files
log.dirs=/usr/local/var/lib/kafka-logs
在磁盘上,一个分区是一个目录,例如主题名为 quickstart-events 的一个分区:
% tree /usr/local/var/lib/kafka-logs/quickstart-events-0/
/usr/local/var/lib/kafka-logs/quickstart-events-0/
├── 00000000000000000000.index
├── 00000000000000000000.log
├── 00000000000000000000.timeindex
└── leader-epoch-checkpoint
其中 index 文件与 log 文件合称为一个 segment,以人类可读的方式查看 log 文件:
% kafka-run-class kafka.tools.DumpLogSegments --deep-iteration --print-data-log --files /usr/local/var/lib/kafka-logs/quickstart-events-0/00000000000000000000.log
Dumping /usr/local/var/lib/kafka-logs/quickstart-events-0/00000000000000000000.log
Starting offset: 0
baseOffset: 0 lastOffset: 0 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 0 CreateTime: 1604900950169 size: 90 magic: 2 compresscodec: NONE crc: 3202290031 isvalid: true
| offset: 0 CreateTime: 1604900950169 keysize: -1 valuesize: 22 sequence: -1 headerKeys: [] payload: This is my first event
baseOffset: 1 lastOffset: 1 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 90 CreateTime: 1604900955215 size: 91 magic: 2 compresscodec: NONE crc: 3852839661 isvalid: true
| offset: 1 CreateTime: 1604900955215 keysize: -1 valuesize: 23 sequence: -1 headerKeys: [] payload: This is my second event
从中可以发现,消息编码在 log 文件中;index 文件则包含了偏移量(offset)与消息在 log 文件中的位置(position)的映射,用于查找消息。
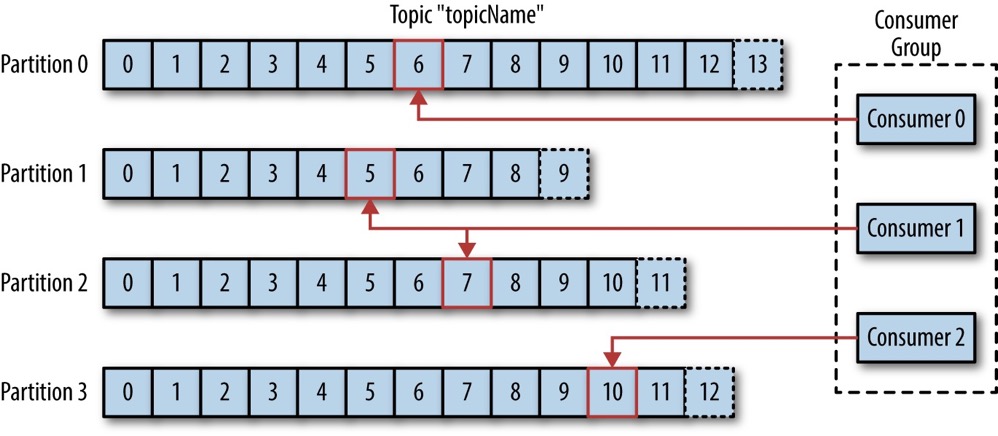
对于消息消费者组(consumer group)来说,从分区读取消息就像从提交日志读取记录;消费者组通过分区的偏移量区分已读消息和未读消息,消费者组对主题(Topic)的分区的偏移量存储在 Zookeeper 树或 Kafka 内置主题中。
毫不夸张地说,Kafka 是一个分布式提交日志系统,只不过官方更愿意称之为分布式事件流平台。
本文首发于 https://h2cone.github.io/
参考资料
- The Log: What every software engineer should know about real-time data’s unifying abstraction
- Wikipedia # Log file
- Wikipedia # Write-ahead logging
- ML Wiki # Undo/Redo Logging
- Intro to undo/redo logging
- Recovering from a system crash using undo/redo-log
- undo log 与 redo log 原理分析
- MySQL 5.7 Reference Manual # The Binary Log
- MySQL 5.7 Reference Manual # mysqlbinlog — Utility for Processing Binary Log Files
- MySQL 5.7 Reference Manual # Replication Formats
- How to keep Elasticsearch synchronized with a relational database using Logstash and JDBC
- How to sync your MySQL data to Elasticsearch
- The Raft Consensus Algorithm
- How Kafka’s Storage Internals Work
- Distributed Commit Logs with Apache Kafka