Kafka 之于 Elastic Stack
背景
刚入行那会,公司产品研发部正如火如荼建设微服务基础设施,其中就包括日志中心。试想一下,包含众多容器化应用程序的系统,一个服务可能会有多个实例,每个实例输出各自的日志记录;假如在客户端收到了来自服务器端的异常响应,例如 500 Internal Server Error,相应的负责人不可避免地会遇到需要通过查看容器日志来查明哪里发生故障或则什么原因导致性能下降的情景。
负责人也许走了弯路。登录哪些服务器或跳板机?有没有访问权?需不需要通过“中介”才能获得许可或相关日志文件?查看哪些结点上的哪些服务的日志?
负责人也以可以走已经铺好的路。直接在日志中心 Web 版搜索所需的一切日志记录;系统中所有服务的日志记录都可以被索引与检索,不仅仅可以用于故障排除,还可以用于监控、告警、数据分析等等。
集中式日志管理
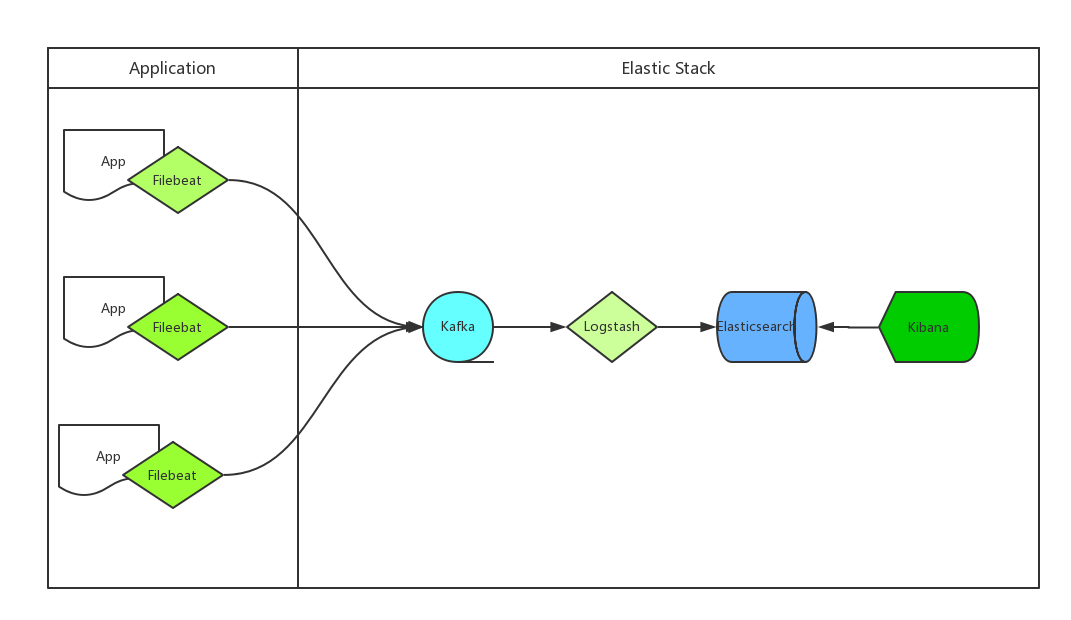
上图来自运维咖啡吧,这是一类典型的日志处理架构。
- Filebeat,轻量级日志采集器。
- 考虑到基于 Docker 开发服务,应用程序的父镜像应包含 Filebeat,例如
FROM 父镜像之后执行一系列下载、安装、设置 Filebeat 的指令。 - Filebeat 作为应用程序的 agent 可以将日志作为输入源(从日志文件读取行),再将 kafka 作为输出目的地(发送日志记录或事件到 Kafka)。
- 考虑到基于 Docker 开发服务,应用程序的父镜像应包含 Filebeat,例如
- Logstash,传输和处理日志、事件等数据。
- 因为 Logstash 有许多输入插件,包括读取来自 Kafka Topic 的事件,可以作为 Kafka 的消费者。
- ELK 中的 Logstash 当然支持将 Elasticsearch 作为输出目的地。
- Elasticsearch,分布式 RESTful 搜索引擎。
- Kibana,可视化 Elasticsearch 数据的用户界面。
有趣的是,Elastic Stack 并不包含 Kafka,但两者在日志/事件处理领域却是经典组合。
何时组合使用 Kafka 与 Elastic Stack
应对突发流量
在大数据领域,Kafka 以单位时间内吞吐量极高著称,所谓吞吐量是指代可处理的记录条数,Kafka 非常适用于流量削峰。早在 2014 年,Kafka 已经能达到每秒 200 万次写入(在三台廉价的机器上)。为什么 Kafka 如此之快?至少有如下原因:
- 基于追加式提交日志,顺序 I/O 飞快。
- 重度使用文件系统缓存。
- 复杂性从生产者转移到了消费者。
- 高度可水平/横向扩展。
Kafka 应对峰值或突发数据的能力远强于 Logstash,可防止单位时间输入过多日志数据导致 Logstash 成为系统的瓶颈;值得注意的是,完成本篇之时,官方的 Logstash 扩展建议也仅有一小段。
当 ES 不可访问
当 Elasticsearch 集群不可访问时(例如升级版本或者其他理由需要暂时下线),Kafka 能够暂时保存 Filebeat 采集的日志数据,直到 Elasticsearch 和 Logstash 再次上线。
扩展和容错
引用一张来自 Kafka: The Definitive Guide 的插图:
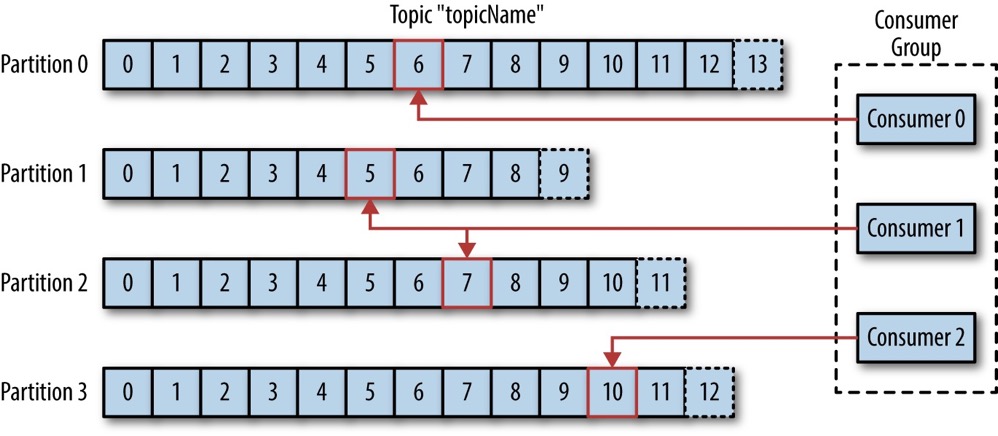
消费者群组(Consumer Group)保证同一个主题(Topic)的任意分区(Partition)最多只能被组内的一个消费者使用。增加 Logstash 实例来组成一个消费者群组,它们将并发读取 Kafka Topic 中的日志消息,而不会交叠,因此能够提升单位时间内从 Kafka 到 Logstash 再到 Elasticsearch 的吞吐量;使用多个 Logstash 实例的另外一个好处是是增强系统的容错能力。
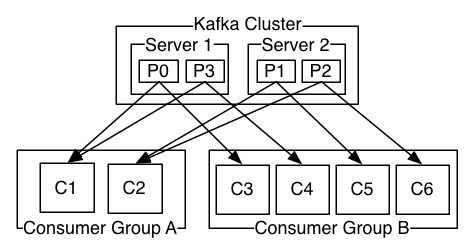
默认情况下,当消费者加入或离开消费者群组将触发再平衡(rebalancing),Logstash 消费者的 Kafka Client 库将参与重新分配分区给消费者的过程。当群组中有若干 Logstash 实例失效时,根据再平衡协议,失去消费者的分区将被分配给现有的消费者。
一点建议
假设 Logstash 实例组成的消费者群组 ID 为 logstash,存储应用程序日志记录的话题 ID 为 app_logs,下面是 logstash-*.conf 的输入源配置:
input {
kafka {
bootstrap_servers => "kafka_host_1:9092,kafka_host_2:9092"
group_id => "logstash"
topics => ["app_logs"]
consumer_threads => 8
...
}
}
其中 consumer_threads 是消费者线程数(默认值是 1),理想情况下,消费者线程数之和应与分区数相等,以实现完美平衡。如果消费者线程数之和多于分区数,那么某些线程将处于空闲状态;如果消费者线程数之和少于分区数,那么某些线程将消费多个分区。举例来说,app_logs 话题的分区数为 16,最佳的部署方式很可能是将消费者线程数为 8 的 2 个 Logstash 实例部署到 2 台 CPU 核数为 8 的机器上。
虽说 Kafka 应对突发数据或流量高峰的能力很强,但是在无法估算日志记录/事件的量级与流速之前应备不时之需。例如,使用一些“突发”主题,当单位时间内应用程序产生过多日志数据时,可以在运行时将其移动到“突发”主题,使其它主题避免不必要的流量。
本文首发于 https://h2cone.github.io/