编译的一些事
一次交叉编译体验
有一个项目使用高级编程语言创建原生进程(native process)来执行 Shell 脚本,其中有一段用于编辑特定配置文件的代码片段。
for name in $names; do
eval expr='$'"$name"
sed -i -e "s/<@${name}@>/${expr}/g" ${file%.*}.${component_instance}
done
sed(stream editor)是一个用于过滤和转换文本的 Unix 程序。
# 将 file.txt 中的 before 就地替换为 after
sed -i -e 's/before/after/g' file.txt
用法还算简单,但是,如果 after 包含特殊字符,比如传递包含正则表达式的多行代码(想象一下 Logstash 配置),运行时将极有可能发生类似错误:unknown option to s'。如果要对特殊字符进行转义,这种方案不仅复杂还易错,甚至可能会更改“间接调用” Shell 脚本的应用程序代码。换个角度,sed 是否有更好的替代品?
感谢使用 Rust 重写一切的开源软件作者们,sd 完全可以代替 sed,而且能识别特殊字符。
sd -s before after file.txt
兴致勃勃从 releases 下载可执行文件,却遇到因为开发/测试环境的 glibc 版本不符合 sd 的要求从而导致无法正常执行。
$ ./sd-v0.7.6-x86_64-unknown-linux-musl --help
./sd-v0.7.6-x86_64-unknown-linux-musl: /lib64/libc.so.6: version `GLIBC_2.18' not found (required by ./sd-v0.7.6-x86_64-unknown-linux-musl)
升级 glibc 有一定风险,管理员不一定允许升级,而且客户/用户也不一定允许在线安装 sd。理想情况下,只需要提前在本地将 sd 源代码编译成目标服务器的可执行代码,那么目标服务器就无需安装 Rust 或其它东西了。得益于 Cross-compile and link a static binary on macOS for Linux with cargo and rust,成功在 macOS Big Sur 上将 sd 源代码编译成开发/测试环境的可执行文件。
$ file sd
sd: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, not stripped
所谓交叉编译,即将源文件从运行编译器的平台生成可在其它平台执行的文件。除了 Rust 天然支持交叉编译 ,其它主流语言做得到吗?Go 开箱即支持交叉编译。
AOT 和 JIT
Java 就麻烦得多了。Oracle Java 编译器(javac)并不能将 Java 源代码(Source Code)编译成原生可执行代码,而只能编译成 Java 字节码(Bytecode)。
Java 字节码通常与平台无关(platform-independent),由 Java 虚拟机的解释器(Bytecode Interpreter)执行(如果有的话)。很久很久以前,Sun 用“编写一次,到处运行”的口号来说明 Java 的跨平台优势,Java 跨平台是因为 Java 虚拟机不跨平台,不同的平台安装不同的 Java 虚拟机才可能运行相同的 Java 程序(不同平台的 Java 字节码解释器可以执行相同的字节码)。
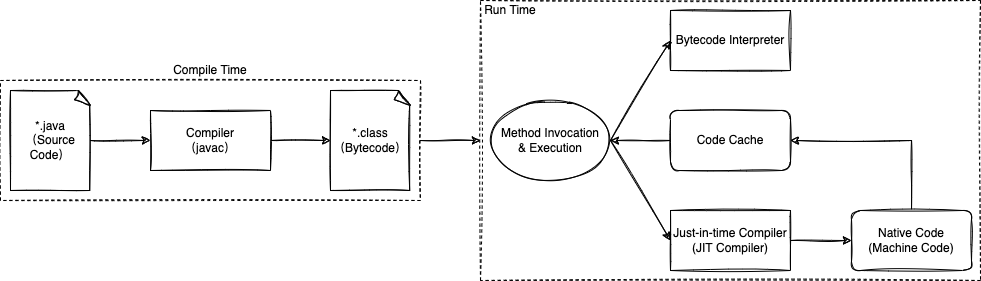
当 Java 字节码由解释器执行时,总是比编译为原生机器码的同一程序执行慢。JIT 编译器(JIT Compiler)专门缓解此问题,JIT 编译器通常在运行时将 Java 字节码编译成原生机器码(Native/Machine Code),又称动态编译。相对地说,静态编译又名 AOT 编译(Ahead-of-time compilation),AOT 编译器的编译过程(从源代码到原生机器码)发生在程序运行之前。
#include <stdio.h>
int main()
{
printf("hello, world\n");
}
一个表面上非常简单的 C 语言程序(hello.c),使用 GCC 编译后输出可执行的目标程序(hello),这个过程包括了 AOT 编译。
% gcc -o hello hello.c
可执行至少意味着可通过 ./ 执行。
% ./hello
hello, world
发生了什么事?了解编译系统如何工作,对将来优化程序性能有益处。

(深入理解计算机系统(原书第3版)1.2 程序被其他程序翻译成不同的格式)
% file hello
hello: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, for GNU/Linux 2.6.32, BuildID[sha1]=dd72445243a497f2f62a1e5d19185ca41181e4b5, not stripped
JIT 编译器通常在预热(warmup)期工作,虽然 Java 程序启动速度会受到影响,但是方法调用(Method Invocation)发生时,Java 虚拟机将通过分析数据(Profiling)积极应用优化。例如,将调用次数已达阈值的方法(热点代码)编译成原生机器码并写入代码缓存(Code Cache),代码缓存的容量可以通过选项 -XX:ReservedCodeCacheSize 设置;将来调用同一方法时,不是解释执行(基于 Stack Machine),而是从缓存读取原生机器码直接执行(基于 Register Machine)。
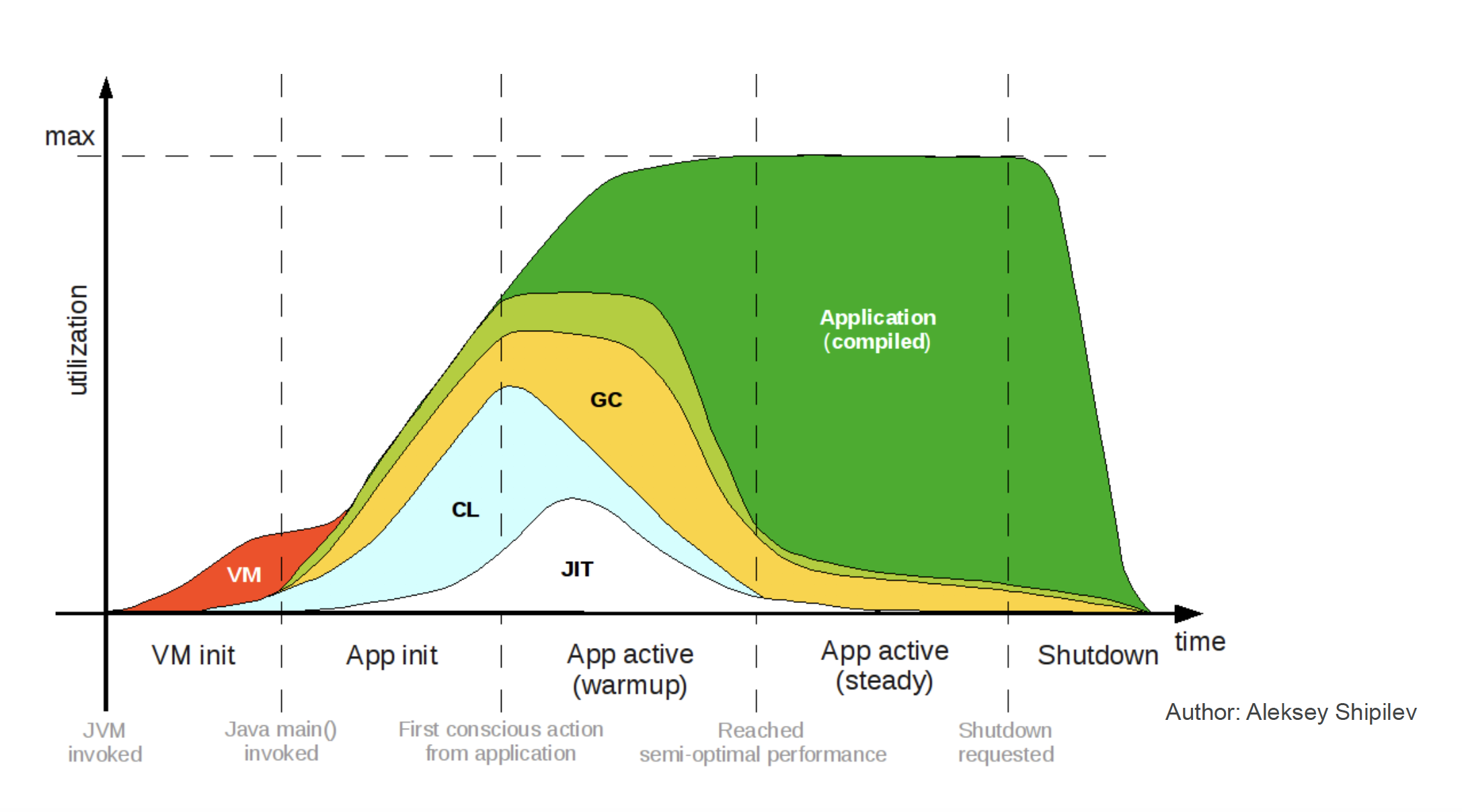
在生成原生机器码之前,JIT 编译器会先积极优化字节码。例如,方法内联(Method Inlining)、逃逸分析(Escape Analysis)、循环展开(Loop unrolling)、锁粗化(Lock Coarsening)、锁清除(Lock Elision) 等等。
由于 Java 虚拟机隐藏了操作系统具体实现的复杂性,并给应用程序提供了简单或统一的接口,随着 Java 虚拟机的迭代升级,即使运行同一程序,也能实现更高的性能。Oracle 的 Java 默认虚拟机是 HotSpot JVM,HotSpot JVM 用 C++ 编写而成,它有两个 JIT 编译器,C1 和 C2。
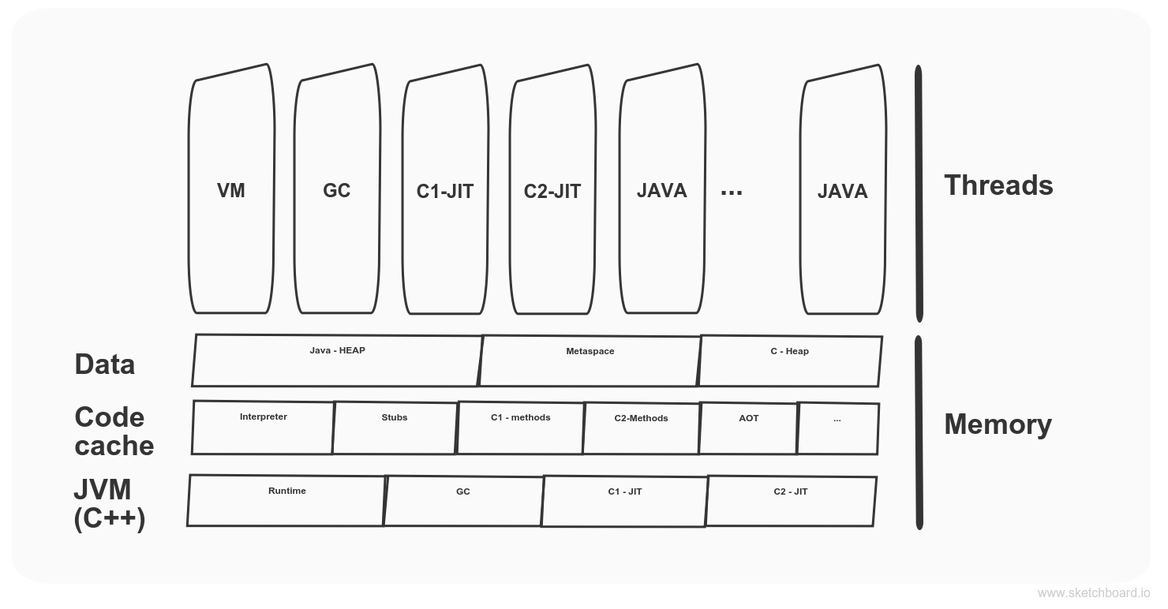
C1 适用于 Client(java –client),启动快,但峰值性能受损;C2 适用于 Server(java –server),非常适合编译热点方法,但启动慢(热身)。权衡利弊的结果可能是组合使用 C1 和 C2,Java 8 后默认开启多层编译(-XX:+TieredCompilation),先以 C1 编译,采样足够后以 C2 编译。
所谓的 JVM 性能调优,通常聚焦在内存与 GC,若不考虑应用程序可能包含低效的部分,那不妨调参(选项或标记) 之后测试是否符合预期。真遇到了需要监视 JIT 的场景,换言之是为了性能优化或故障排查的目的分析 JIT 日志,发觉日志难读,但好在发现一款 JIT 日志分析与可视化工具——jitwatch。
GraalVM 和 LLVM
退一步来说,借助虚拟机可以在编译时将 Java 程序编译成可执行文件。Oracle 的 GraalVM 的附加组件包括了一种将 Java 应用程序 AOT 编译为原生可执行文件的技术,名为 Native Image。
GraalVM 是用于运行以 JavaScript、Python、Ruby、R、基于 JVM 的语言(例如 Java、Scala,Clojure,Kotlin)、基于 LLVM 的语言(例如 C 和 C ++)编写的应用程序的通用虚拟机。
GraalVM Native Image 技术存在不容忽视的限制,原因之一是 AOT 编译参考的静态信息有时是不够的,并且很难猜测应用程序的实际行为。为了能够构建高度优化的原生可执行文件,GraalVM 会运行积极的静态分析,在编译时必须知道所有可访问的类和字节码,否则 Java 的动态特性(例如动态类加载、反射、动态代理等等)严重受限,甚至不可用。因此,GraalVM Native Image 兼容和优化指南建议用户编写配置文件“提示” GraalVM 做正确的事情。
GraalVM Native Image 暂不支持交叉编译,但不意味不能在一个平台构建出其它平台的可执行文件。运用 操作系统级别的虚拟化即可,例如在本地下载各个平台的 GraalVM Docker 镜像,以此为基础构建可执行文件的镜像。
GraalVM 之所以能运行不同种类的语言编写而成的应用程序的原因之一是 GraalVM 的核心组件与附加组件包含了多种运行时(Runtime)。比如运行 Java、JavaScript/Node.js、C/C++ 程序所需的环境:
- Java HotSpot VM
- Node.js JavaScript runtime
- LLVM runtime
LLVM 是模块化和可重用的编译器与工具链技术的集合。
LLVM 不是通用虚拟机(VM),但使用 LLVM 的编程语言非常之多(从LLVM 的维基百科词条第二段可以体会到)。
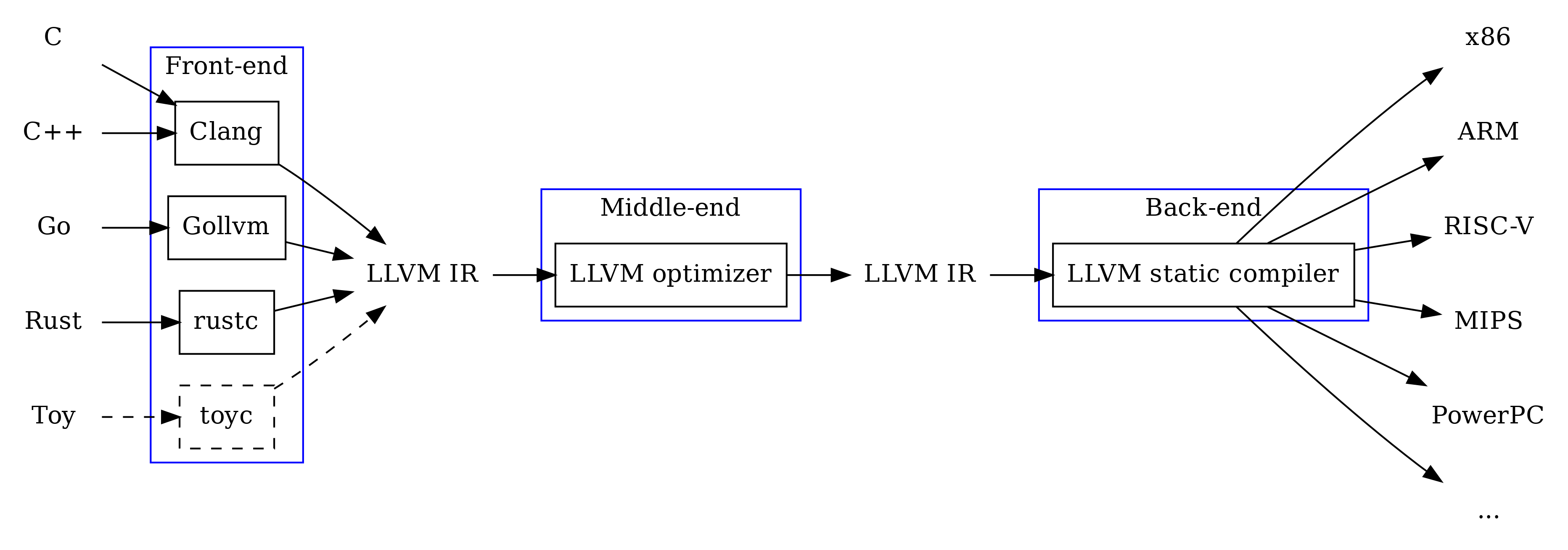
LLVM 编译器通常分为三部分:前端(frond-end)、中端(middle-end)、后端(back-end)。
- 前端:将源码编译为 IR。
- 中端:优化 IR。
- 后端:将 IR 编译为机器码。
IR 是中间表示(Intermediate representation)的简称,它是一种与平台无关(platform-independent)的代码/指令。
% clang-11 hello.c -o hello
例如,使用 Clang 编译简单的 C 语言程序(hello.c),最终得到其可执行文件(hello,如果想观看 LLVM IR 的模样,不妨试试在浏览器编译 C 语言程序)。
% file hello
hello: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, for GNU/Linux 2.6.32, BuildID[sha1]=bf54bb50604533e477e6e42d576c573f88f2a986, not stripped
当我们想创建新的编程语言时,可以不必花费时间和精力去重新发明那些特定的轮子(例如用于编译与优化的工具),而是直接使用 LLVM 实现语言。
从编译时开始重用
程序员们日常使用的各种库(Library)或框架(Framework)总是从编译时开始重用(Reuse),那时,彷佛站在了巨人的肩膀上。
本文首发于 https://h2cone.github.io/