浅谈 Raft
重要的事情
启发式问题
共识是什么?共识算法的应用场景?
共识是分布式系统最重要的抽象之一,著名的《Designing Data-Intensive Applications》展示了全景式的分布式系统,其中有一大章探讨一致性与共识的内容。
共识问题通常形式化描述如下:一个或多个结点可以提议某些值,由共识算法来决定最终值。
“通俗理解,共识是让几个结点就某项提议达成一致。例如,多个人同时尝试预订飞机的最后一个座位或剧院中的同一座位,或者尝试使用相同的用户名注册账户,此时可以用共识算法来决定这些不相容的操作之中谁是获胜者。”
对于本地或共享内存的唯一性问题,直截了当的解决方案是使用锁,但到了分布式系统,复杂度骤然上升,共识可能是唯一可靠的方法。不止于此,共识算法可以应用于分布式系统的一系列问题:
- 可线性化的比较-设置寄存器。寄存器需要根据当前值是否等于输入的参数,来自动决定接下来是否应该设置新值。
- 原子事务提交。数据库需要决定是否提交或中止分布式事务。
- 全序广播。消息系统要决定以何种顺序发送消息。
- 锁与租约。当多个客户端争抢锁或租约时,要决定其中哪一个成功。
- 成员/协调服务。对于失败检测器(例如超时机制),系统要决定结点的存活状态(例如基于会话超时)。
- 唯一性约束。当多个事务在相同的主键上试图井发创建冲突资源时,约束条件要决定哪一个被允许,哪些违反约束因而必须失败。
Raft 可能是最易于理解的共识算法,标杆式的实现是 etcd/raft,其它的实现可以在这里找到。
为什么需要 Leader 或 Primary 或 Master 这类角色的选举?
向客户端制造了单一服务端点的假象,客户端与系统的通信简化为与单一服务端的通信。
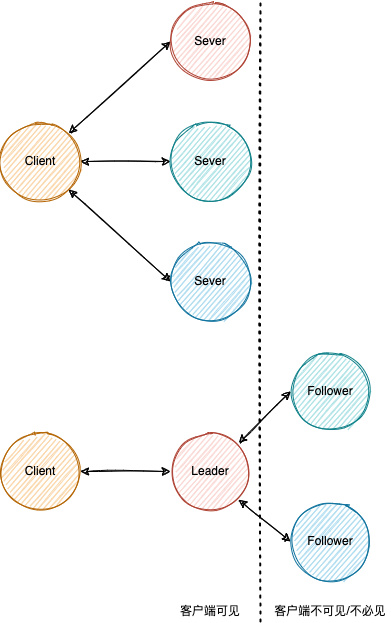
有一种无主结点数据复制(leaderless replication)声称,如果 w + r > n,则读写的结点中一定包含最新值(n 是副本数,写入需要 w 个结点确认,读取必须至少查询 r 个结点)。如果写入了 w 个结点,则需要读取多于 n - w 个结点保证包含最新值(想象一下 w 个结点与 r 个结点有重叠),因此 r > n - w -> r + w > n,这被称为 Quorum,但现实情况往往更加复杂,不保证一定能读取到最新值。
为单一 Leader 编写程序可能比采用 Quorum 等其它方法更容易,但是劣势也很明显,例如单点失效发生在唯一的 Leader 身上,那恢复期间服务不可用?客户端可以重试,直到一名新的 Leader 被选举出来;更严重的缺陷是唯一的 Leader 负载过高时,会成为了系统的性能瓶颈。早有耳闻 TiKV 是基于 Raft 的分布式键值对数据库,其扩展方式是通过数据分区与 Raft 组(raft group)。
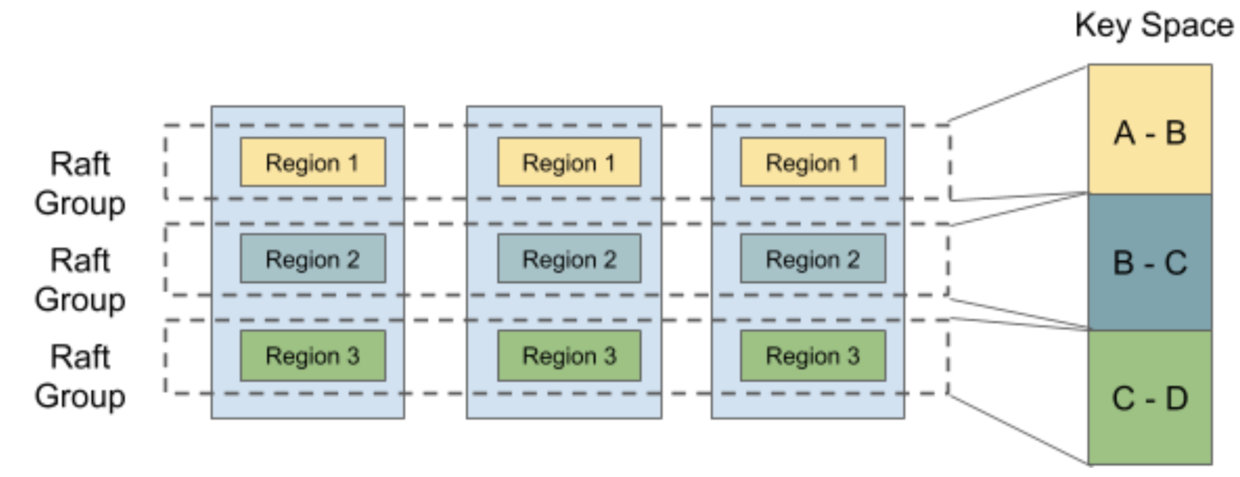
如上图所示,数据分布到 3 个分区(Region),每个分区通过 Raft 的数据复制方法得到 3 个数据副本(1 Leader + 2 follower),虽然 Raft 组之间并无一致性的要求,但是优势已经非常明显的了。
Follower 何时转为 Candidate?Candidate 何时转为 Leader?Leader 何时转为 Follower?
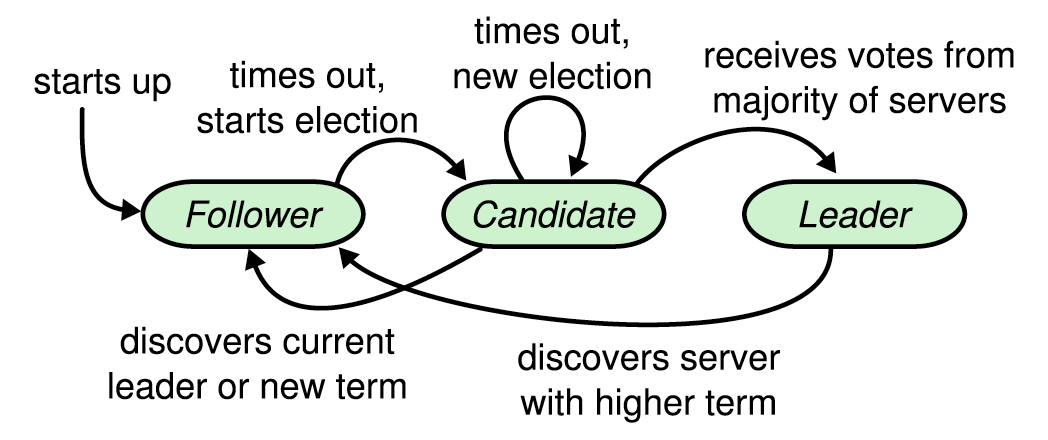
Raft 集群中的 Server 可以是 Leader,也可以是 Follower,还可以是选举中(Leader 不可用时)的 Candidate。Leader 负责将日志复制到 Followers(一种数据复制方法,名为状态机复制)。Leader 通过发送“心跳”定期通知 Follower 们它的存在。每个 Follower 都有一个倒计时(election timeout),接收到“心跳”时,将重置该倒计时,若没接收到,则转为 Candidate,开始 Leader 选举。
每个 Server 的 Election timeout 不应是相等或者过于相近,否则容易出现多个 Candidate 同时请求投票的局面,很可能发生 Split vote。
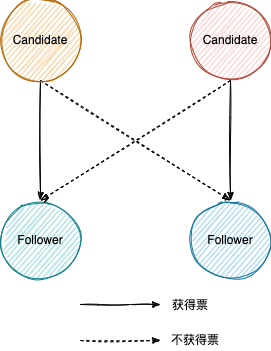
一旦获得了多数票,Candidate 就能提升为 Leader,所谓多数(majority)等于结点数量除以 2 的结果向下取整,比如 3 / 2 == 1、4 / 2 == 2、5 / 2 == 2。
结点之间如何通信?允许 Candidates 并发请求投票(request votes)?结点如何响应?
通常是 RPC,Server 可发送两类消息,一是 RequestVotes,二是 AppendEntries,分别用于 Leader 选举、心跳与日志复制。当然,但是每个 Server 在一个期数(term)最多只能投一票,Candidate 一定会投给自己一票,接收到投票请求的 Follower 最多回应一票。Term 是单调递增的整数变量,在开始 Leader 选举时递增,每个 Server 都维护着各自的 Term。
一旦发生了 Split vote,由于多个 Candidate 都不能获得多数票(参考上图 4 结点的情景),只能递增 Term,开始新的选举。为了快速的选出 Leader 以提供服务,Election timeout 通常在 150 到 300 毫秒之间,最好运大于广播时间(向一组结点发送请求到接收响应的平均时间)且远小于 MTBF。
如何解决脑裂?
虽然某一任期最多只有一位 Leader,但是 Raft 集群可能因为网络分区,分裂成若干子集群。
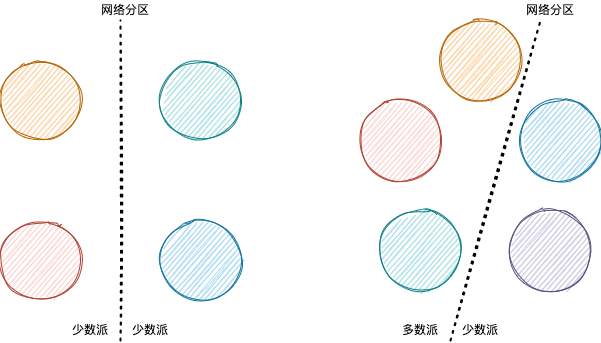
上文分析可以知道,少数派无法选举出新 Leader,只有多数派做得到。网络分区修复后,Term 较大的 Leader 会把 Term 较低 的 Leader 赶下台(discovers server with higher term)。
为什么需要复制日志(replicated log)?
日志是分布式系统最重要的抽象之一。写日志优先于执行来自客户端的命令,日志先行技术有不少优势,一是追加式更新较快,二是适合增量同步数据,三是满足数据恢复与强一致性要求。
为什么 Leader 执行来自客户端的命令前先写日志?Leader/Follower 何时提交日志条目?又何时应用数据变更(执行命令)?
假设不写日志或者先执行一系列命令,当某些命令执行失败了(没有真正持久化这件事客户端不一定知道),那相当于这些命令彻底丢失了;相反,先写日志后执行命令,至少可能发生一件命令已备份(日志条目包含命令)的事件,也就拥有了更强的容错性。值得一提的是,写日志当然也可能失败,退化成与执行来自客户端的命令一样,提示客户端失败或重试。

如何保证结点之间复制日志的一致性?结点故障、网络分区、不一致时如何恢复?
有些日志比另一些日志更新(more up-to-date)。Raft 通过比较最后一个日志条目来决定哪个 Server 的日志较新。
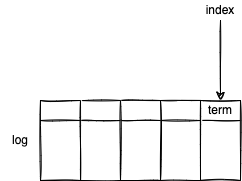
- 最后一个日志条目的 term 不等时,term 越大则越新。
- 最后一个日志条目的 term 相等时,日志越长则越新。
对于 Server 之间的日志冲突,Raft 倾向于修复较旧的日志,使其与较新的日志保持一致。
基于 Raft 的系统如何保证可靠性?换言之,如何容错(可用性与一致性)?例如结点故障、网络分区等。
除了日志一致性、Raft 组、最佳的 Election timeout,如果 Follower 崩溃了,虽然其它 Server 发送消息给 Follower 失败了,但是 Server 会重试,直到 Follower 上线后回应确认消息;如果请求在失败之前已经被考虑,重启的 Follower 将忽略它。
本文首发于 https://h2cone.github.io/