通过 Azure OpenAI API 接入 ChatGPT
写在前面
上个月参与公司将 LLM 应用到基于 Spring Boot 的业务系统差事:接入 ChatGPT。
Azure OpenAI Service
Azure OpenAI 服务允许通过 REST API 访问 OpenAI 的强大语言模型,包括 GPT-3、Codex 和 Embeddings 模型系列。 这些模型可以轻松适应特定的任务,包括但不限于内容生成、汇总、语义搜索和自然语言到代码的转换。用户可以通过 REST API、Python SDK 或 Azure OpenAI Studio 中基于 Web 的界面访问该服务。
使用 Azure OpenAI 服务在大部分情况下不需要代理,无严格网络封锁。
依赖库
后端
- TheoKanning/openai-java。Java 中的 OpenAI GPT-3 API 客户端。
- knuddelsgmbh/jtokkit。JTokkit 是一个 Java 分词器库,设计用于 OpenAI 模型。
前端
- mpetazzoni/sse.js。一个灵活的 JavaScript SSE 库。
认证
与 OpenAI API 的 header 要求包含 Authorization: Bearer $OPENAI_API_KEY 不同的是,Azure OpenAI API 的 header 要求包含 api-key: $OPENAI_API_KEY,详情参考 Azure OpenAI Service REST API reference。
提示与补全
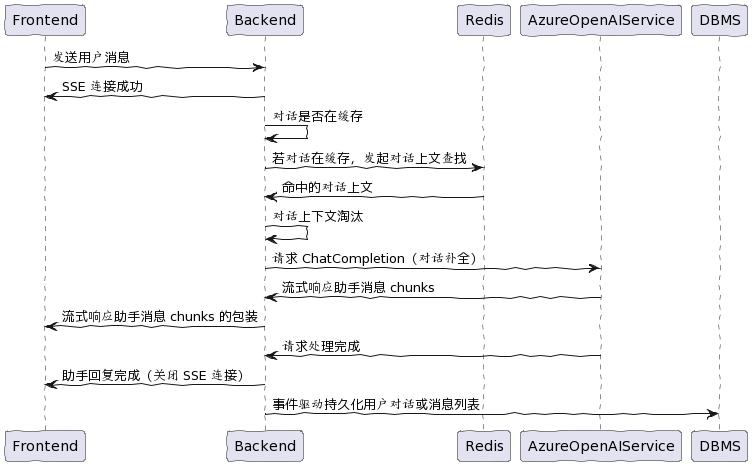
在与 LLM 对话的过程中,流式响应体验比阻塞式响应好很多。
public interface ChatApi extends OpenAiApi {
@Streaming
@POST("{deployment}/chat/completions")
Call<ResponseBody> createChatCompletionStream(
@Body ChatCompletionRequest request,
@Path("deployment") String deployment,
@Query("api-version") String version
);
}
自定义 API 客户端与覆写接口可以使用 OpenAI API 风格的 Java 库调用 Azure OpenAI API。
@Getter
private ChatApi chatApi;
private ChatApi chatApi() {
OkHttpClient httpClient = new OkHttpClient.Builder().addInterceptor(chain -> {
Request rawRequest = chain.request();
Request request = rawRequest.newBuilder()
.header(headerName, StrUtil.isBlank(headerPrefix) ? key : headerPrefix + key)
.header(Header.CONTENT_TYPE.getValue(), ContentType.JSON.getValue())
.method(rawRequest.method(), rawRequest.body())
.build();
return chain.proceed(request);
}).addInterceptor(chain -> {
Request request = chain.request();
Response response = chain.proceed(request);
Assert.notNull(response);
if (!response.isSuccessful()) {
ResponseBody body = response.body();
String bodyStr = Objects.nonNull(body) ? body.string() : null;
log.warn("{} {} -> {} {} {}", request.method(), request.url(), response.code(), response.message(), bodyStr);
BaseResponse<?> baseResponse = JSONUtil.toBean(bodyStr, BaseResponse.class, true);
if (Objects.nonNull(baseResponse.getError())) {
String message = baseResponse.getError().getMessage();
log.error("!chatApi|{}", message);
}
ErrorCode.OPENAI_API_NOT_AVAILABLE.throwOut();
}
return response;
})
.connectTimeout(timeout, TimeUnit.SECONDS)
.writeTimeout(timeout, TimeUnit.SECONDS)
.readTimeout(timeout, TimeUnit.SECONDS)
.build();
return new Retrofit.Builder()
.baseUrl(baseUrl)
.client(httpClient)
.addCallAdapterFactory(RxJava2CallAdapterFactory.create())
.addConverterFactory(JacksonConverterFactory.create(OBJECT_MAPPER))
.build()
.create(ChatApi.class);
}
Chat API 客户端用法如下所示:
@Override
public Flowable<ChatCompletionsChunk> chatCompletionStream(ChatCompletionsRequest request) {
request.setStream(true);
String deployment = conf.modelDeployment.get(request.getModel());
return OpenAiService.stream(chatApi.createChatCompletionStream(request, deployment, conf.version), ChatCompletionsChunk.class);
}
SSE 接口
在 Spring Boot 程序开发 SSE 接口参考了 Server-Sent Events in Spring。
@ApiOperation("发送消息")
@PostMapping("/conversation")
public SseEmitter conversation(@RequestBody ConversationParam param) throws InterruptedException {
String username = JwtUtils.currentUser();
Assert.notBlank(username, ErrorCode.ACCOUNT_NOT_EXISTS);
param.setUid(username);
final SseEmitter emitter = new SseEmitter();
final SecurityManager securityManager = SecurityUtils.getSecurityManager();
param.setStream(true).setEmitter(emitter).setSecurityManager(securityManager);
chatService.sendMessageAsync(param);
return emitter;
}
除了 SSE,也可以考虑使用 WebSocket 发送消息,ChatGPT 和 New Bing 是两派的代表。
上下文淘汰
由于 gpt-3.5-turbo 的 Tokens 限制为 4096,一种粗暴的策略是当预计的对话上下文超过上限时丢弃较早的消息。
while (conv_history_tokens + max_response_tokens >= token_limit):
del conversation[1]
conv_history_tokens = num_tokens_from_messages(conversation)
简言之,请求 Tokens + 最大响应 Tokens < 模型 Tokens 限制,其中 Tokens 计算参考:
def num_tokens_from_messages(messages, model="gpt-3.5-turbo-0301"):
encoding = tiktoken.encoding_for_model(model)
num_tokens = 0
for message in messages:
num_tokens += 4 # every message follows <im_start>{role/name}\n{content}<im_end>\n
for key, value in message.items():
num_tokens += len(encoding.encode(value))
if key == "name": # if there's a name, the role is omitted
num_tokens += -1 # role is always required and always 1 token
num_tokens += 2 # every reply is primed with <im_start>assistant
return num_tokens
按升序丢弃消息可能会出现丢失与用户提示有关的消息或携带与用户提示不相关的内容发送到 LLM,结果是回复效果不好,调用成本较高。观察到市面上一些处理长文本的 LLM 应用使用 LlamaIndex (GPT Index) “绕过” Tokens 限制,它通过 Embeddings 模型与本地数据库查找与用户提示相关的段落,然后从这些段落中生成 Prompt 喂给 LLM。
比 GPT Index 封装程度还高的另一个 Python 库 langchain 的玩法是真的多……
本文首发于 https://h2cone.github.io/