流式处理 gzip
需求背景
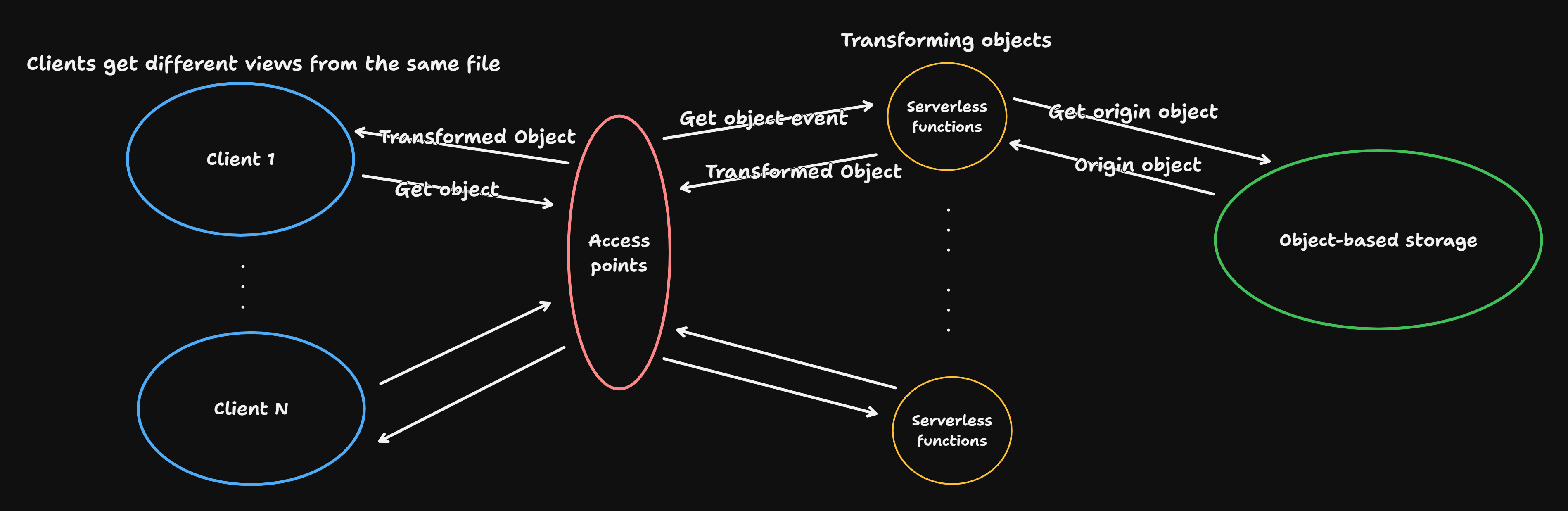
不同的客户从服务端获取相同对象时返回不同的文件视图。待处理的文件是 gzip 压缩的文本文件,既不希望在处理过程中产生文件存储开销,也不希望 TTFB 过长影响客户体验。刚好 gzip 压缩算法基于 Deflate,允许在处理数据时逐块进行解压或压缩,而不需要一次性将整个数据加载到内存中。如果是在 Amazon S3 存储压缩文件,那么 Amazon S3 Object Lambda 是配套的解决方案。面向 Serverless 计算,我们的函数在运行时受到云厂商配额的限制:内存、时间、空间、并发等。因此,我们需要在处理文件时,尽可能减少内存占用,同时提高执行效率。
心路历程
解压
刚开始学习使用 reqwest 来获取文本文件,结合各种异步库来流式读取文件内容。
use futures::TryStreamExt;
use tokio::io::AsyncBufReadExt;
use tokio_util::io::StreamReader;
let url = "..."
let resp = reqwest::get(url).await?;
let stream = resp.bytes_stream();
let stream_reader = StreamReader::new(stream.map_err(|e| std::io::Error::new(std::io::ErrorKind::Other, e)));
let reader = tokio::io::BufReader::new(stream_reader);
let mut lines = reader.lines();
while let Some(line) = lines.next_line().await? {
// ...
}
紧接着,注意到 Rust 团队维护的 flate2-rs 可以用来流式压缩/解压 *.gz 文件,但是它与 reqwest 组合起来不太顺畅,因为从 pull/292 可以确认它被社区移除了 tokio 支持。转而开始探索其它库,比如 async-compression,它支持异步 I/O 类型 futures-rs。
use async_compression::futures::bufread::GzipDecoder;
use futures::io::{self, BufReader, ErrorKind};
use futures::stream::StreamExt;
use futures::{AsyncBufReadExt, TryStreamExt};
let stream = reqwest::get(url)
.await?
.bytes_stream()
.map_err(|e| io::Error::new(ErrorKind::Other, e))
.into_async_read();
let stream_reader = BufReader::new(stream);
let decoder = GzipDecoder::new(stream_reader);
let reader = BufReader::new(decoder);
let mut lines = reader.lines();
while let Some(line_res) = lines.next().await {
// ...
}
糊上了一层又一层的“胶水”:
- 依赖 reqwest 启用了
stream,以便获取响应字节流。 - 引用 TryStreamExt 将响应字节流转化为实现了
AsyncRead的异步 I/O 类型。 - 使用
BufReader从异步的响应字节流创建 stream reader。 - 从 stream reader 创建面向 Buffer 读的
GzipDecoder。 - 这里 GzipDecoder 也实现了 AsyncRead,创建解压的 reader。
- 依赖
AsyncBufReadExt和StreamExt从解压的 reader 读取每一行。
压缩
由于我们不打算将解压后的文件存储到本地,而是在替换一行后将这一行写入 GzipEncoder 的 buffer,众所周知,8 位表示 1 字节,因此用基于固定容量的 Vec<u8> 表示 GzipEncoder 的 buffer。
// 2*2^12 B = 8 KB
let buf_cap = 2 << 12;
let mut encoder = GzipEncoder::new(Vec::with_capacity(buf_cap));
while let Some(line_res) = lines.next().await {
if let Err(e) = line_res {
eprintln!("Error reading line: {}", e);
break;
}
let line = line_res.unwrap();
replace_line(line, &mut encoder, buf_cap).await?;
}
encoder.shutdown().await?;
let buffer = encoder.get_ref();
process_chunk(buffer).await?;
其中函数 replace_line 和 process_chunk 的意思如下所示:
async fn replace_line(
line: String,
encoder: &mut GzipEncoder<Vec<u8>>,
limit: usize,
) -> Result<(), Box<dyn std::error::Error>> {
// e.g. Replace all lines starting with "#CHROM" to lowercase
if line.starts_with("#CHROM") {
encoder.write_all(line.to_lowercase().as_bytes()).await?;
} else {
encoder.write_all(line.as_bytes()).await?;
}
encoder.write_all(b"\n").await?;
// Flush the buffer if exceeds the limit
if encoder.get_ref().len() >= limit {
let buffer = encoder.get_mut();
process_chunk(buffer).await?;
buffer.clear();
}
Ok(())
}
async fn process_chunk(chunk: &[u8]) -> Result<(), Box<dyn std::error::Error>> {
// e.g. Write to stdout
tokio::io::stdout().write_all(chunk).await?;
Ok(())
}
持续向 GzipEncoder<Vec<u8>> 写入大文件的数据块,有内存分配风险,因此当 buffer 遇到上限时,我们需要将 buffer 交给 process_chunk,紧接着清空 buffer,周而复始。完整数据大小可能不是 limit 的整数倍,因此在循环退出后关闭 encoder,处理剩余数据块。
同步
对于在线服务,可能会将压缩数据写入响应流或发送到其它数据系统,使用 Channel 可以解耦生产者和消费者,同时保证数据的次序。
let (tx, mut rx) = mpsc::channel(buf_cap);
tokio::spawn(async move {
while let Some(line_res) = lines.next().await {
if let Err(e) = line_res {
eprintln!("Error reading line: {}", e);
break;
}
let line = line_res.unwrap();
replace_line(line, &mut encoder, &tx, buf_cap)
.await
.unwrap();
}
encoder.shutdown().await.unwrap();
let buffer = encoder.get_ref();
tx.send(buffer.clone()).await.unwrap();
drop(tx);
});
while let Some(buffer) = rx.recv().await {
process_chunk(&buffer).await.unwrap();
}
修改函数 replace_line,在清空 buffer 之前将数据块发送到 Channel。
async fn replace_line(
line: String,
encoder: &mut GzipEncoder<Vec<u8>>,
limit: usize,
sender: &mpsc::Sender<Vec<u8>>,
) -> Result<(), Box<dyn std::error::Error>> {
// e.g. Replace all lines starting with "#CHROM" to lowercase
if line.starts_with("#CHROM") {
encoder.write_all(line.to_lowercase().as_bytes()).await?;
} else {
encoder.write_all(line.as_bytes()).await?;
}
encoder.write_all(b"\n").await?;
// Flush the buffer if exceeds the limit
if encoder.get_ref().len() >= limit {
let buffer = encoder.get_mut();
sender.send(buffer.clone()).await?;
buffer.clear();
}
Ok(())
}
到这里已经成功一半了,完整代码在 gzstream,之后将它封装成 Lambda 部署到云端就是另外一段故事了。
本文首发于 https://h2cone.github.io/